03 Grundlagen des Testens: Unit Testing - Äquivalenzklassen
November 2025 (17197 Words, 96 Minutes)
Kapitel 03: Unit Testing - Äquivalenzklassen
Voraussetzungen: Diese Vorlesung setzt Kapitel 03 (Testing-Grundlagen): Testing-Grundlagen - Basics fort. Stellen Sie sicher, dass Sie die Testing-Pyramide, das AAA-Muster und Clean Code Prinzipien verstehen, bevor Sie fortfahren.
1. Einführung: Das Testauswahl-Problem
In Teil 1 haben wir gelernt:
- Wie man Unit-Tests mit pytest schreibt
- Das AAA-Muster (Arrange-Act-Assert)
- Clean Code Prinzipien für Tests
Aber wir haben eine entscheidende Frage übergangen: Welche Tests sollten Sie schreiben?
Betrachte eine einfache Funktion:
def reciprocal(x: float) -> float:
return 1.0 / x
Es gibt unendlich viele mögliche Eingaben. Sie können nicht alle testen. Wie wählen Sie aus?
Diese Vorlesung beantwortet diese Frage mit Äquivalenzklassen-Partitionierung - einem systematischen Ansatz zur Auswahl von Testfällen, der die Abdeckung maximiert und Redundanz minimiert.
1.1 Äquivalenzklassen: Sie zu finden ist schwer
Wir haben festgestellt, dass erschöpfendes Testen unmöglich ist (Abschnitt 5.3), also brauchen wir eine intelligentere Strategie. Diese Strategie ist Äquivalenzklassen-Partitionierung - das Gruppieren ähnlicher Eingaben und das Testen von Repräsentanten aus jeder Gruppe. Das funktioniert gut für einfache Fälle, aber Äquivalenzklassen zu finden wird dramatisch schwerer, wenn Funktionen komplexer werden.
Was ist eine Äquivalenzklasse? (Zugängliche Definition)
Äquivalenzklasse: Eine Menge von Eingaben, die erwartungsgemäß auf die gleiche Weise von der zu testenden Funktion verarbeitet werden und die gleiche Kategorie von Ausgabe oder Verhalten produzieren.
In einfachen Worten:
- Eine Äquivalenzklasse gruppiert Eingaben, die sich ähnlich verhalten sollten
- Alle Eingaben innerhalb einer Teilmenge sollten die gleichen Code-Pfade auslösen und ähnliches Verhalten produzieren
- Wenn eine Eingabe in einer Klasse ihren Test besteht, nehmen wir an, dass alle Eingaben in dieser Klasse ebenfalls bestehen würden
- Wenn eine fehlschlägt, nehmen wir an, dass die gesamte Klasse ein Problem hat
Wichtige Eigenschaften:
- Disjunkt: Keine Eingabe gehört zu mehreren Klassen
- Vollständig: Jede mögliche Eingabe gehört zu genau einer Klasse
- Repräsentatives Testen: Teste einen Wert aus jeder Klasse (nicht alle Werte)
Das mathematische Fundament (Für die Neugierigen)
Für diejenigen, die mit Mathematik vertraut sind, hier ist die präzise Definition, die erklärt warum Äquivalenzklassen funktionieren:
Gegeben:
- Eine Funktion \(f: D\subset \mathbb{R} \rightarrow \mathbb{R}\) (Definitionsbereich → Wertebereich)
- Eine Partition des Ausgabe-Wertebereichs in Ausgabekategorien \(C_1, C_2, \ldots, C_n\)
Definiere eine Äquivalenzrelation auf Eingaben:
\[x \sim y \iff f(x) \text{ und } f(y) \text{ gehören zur gleichen Ausgabekategorie } C_i\]Das bedeutet: “Zwei Eingaben \(x\) und \(y\) sind äquivalent, wenn ihre Ausgaben in die gleiche Kategorie fallen.”
Dann sind die Äquivalenzklassen:
\[E_i = \{ x \in D : f(x) \in C_i \}\]Jede Äquivalenzklasse \(E_i\) ist die Menge aller Eingaben, die auf Ausgabekategorie \(C_i\) abbilden.
Kritische Einsicht: Die Anzahl der Äquivalenzklassen entspricht der Anzahl der Ausgabekategorien, die Sie definieren!
- Wähle 3 Ausgabekategorien → erhalte 3 Äquivalenzklassen
- Wähle 4 Ausgabekategorien → erhalte 4 Äquivalenzklassen
- Die Partition ist eine Wahl basierend darauf, was fürs Testen wichtig ist
Beispiel mit reciprocal(x) = 1/x:
Wenn wir den Ausgabe-Wertebereich partitionieren als: \(\{\text{positiv}, \text{negativ}, \text{Fehler}\}\)
Dann sind die Eingabe-Äquivalenzklassen:
- \(E_1 = \{x : x > 0\}\) (Eingaben, die positive Ausgaben produzieren)
- \(E_2 = \{x : x < 0\}\) (Eingaben, die negative Ausgaben produzieren)
- \(E_3 = \{x : x = 0\}\) (Eingaben, die Fehler produzieren)
Beachte: \(E_1 \cup E_2 \cup E_3 = \mathbb{R}\) (alle reellen Zahlen) - die Vereinigung deckt den gesamten Eingabebereich ab!
1.1.1 Generalisierung auf Mehrere Dimensionen
Die obige Definition funktioniert für beliebige Eingabe- und Ausgabedimensionen:
Für eine Funktion \(f: \mathbb{R}^n \rightarrow \mathbb{R}^m\) (n Eingaben, m Ausgaben):
- Partitioniere den m-dimensionalen Ausgaberaum \(\mathbb{R}^m\) in Kategorien \(C_1, C_2, \ldots, C_k\)
- Jedes \(C_i \subseteq \mathbb{R}^m\) ist eine Teilmenge des Ausgaberaums
-
Die Äquivalenzklassen partitionieren den n-dimensionalen Eingaberaum \(\mathbb{R}^n\):
\[E_i = \{ (x_1, x_2, \ldots, x_n) \in \mathbb{R}^n : f(x_1, \ldots, x_n) \in C_i \}\] -
Die Vereinigung deckt den gesamten Eingabebereich ab:
\[E_1 \cup E_2 \cup \cdots \cup E_k = \mathbb{R}^n\]
Beispiele aus dieser Vorlesung:
| Funktion | Eingaberaum | Ausgaberaum | Partitionierung |
|---|---|---|---|
reciprocal(x) |
\(\mathbb{R}\) (1D) | \(\mathbb{R} \cup \{\text{Fehler}\}\) (1D + Fehler) | 3 Ausgabekategorien → 3 Eingabeklassen |
reciprocal_sum(x,y,z) |
\(\mathbb{R}^3\) (3D) | \(\mathbb{R} \cup \{\text{Fehler}\}\) (1D + Fehler) | 3 Ausgabekategorien → 3 Eingabeklassen |
calculate_ray_slope(angle) |
\(\mathbb{R}\) (1D) | \(\mathbb{R} \cup \{\text{None}\}\) (1D + Spezial) | 4 Ausgabekategorien → 4 Eingabeklassen |
find_intersection(...) |
\(\mathbb{R}^n \times \mathbb{R} \times \mathbb{R} \times \mathbb{R}\) | \(\mathbb{R}^3 \cup \{(None, None, None)\}\) | Viele Kategorien → viele Klassen |
Wichtige Einsicht: Unabhängig von den Dimensionen:
- Sie partitionieren den Ausgaberaum (welche Dimension auch immer)
- Das induziert eine Partition des Eingaberaums (welche Dimension auch immer)
- Die Anzahl der Eingabe-Äquivalenzklassen entspricht der Anzahl der Ausgabekategorien, die Sie definieren
Warum das wichtig ist:
reciprocal_sum(x,y,z)nimmt 3 Eingaben, hat aber nur 3 Äquivalenzklassen (nicht 3³ = 27!)- Die Ausgabe ist eindimensional (nur ein Float), partitioniert in {positiv, negativ, Fehler}
- Alle Eingabetripel
(x,y,z), die positive Ausgabe produzieren, bilden EINE Äquivalenzklasse, unabhängig von individuellen Vorzeichen
1.1.2 Wie wähle ich die Ausgabekategorien \(C_1, C_2, \ldots, C_n\)? Ist das eindeutig?
Kurze Antwort: Nein, die Wahl ist NICHT eindeutig! Sie wählen basierend darauf, was für Ihre Testziele wichtig ist.
Die mathematische Definition sagt uns:
- Partitioniere den Ausgaberaum in Kategorien \(C_1, C_2, \ldots, C_n\)
- Das induziert die Eingabe-Äquivalenzklassen \(E_1, E_2, \ldots, E_n\)
Aber sie sagt uns nicht, WIE wir partitionieren sollen! Das ist eine Design-Entscheidung basierend auf:
1. Welches Verhalten ist Ihnen wichtig?
Für reciprocal(x) = 1/x könnten Sie wählen:
Grobe Partition (2 Ausgabekategorien):
- \(C_1 = \{\text{gültige Ausgabe}\}\) (jede reelle Zahl)
- \(C_2 = \{\text{Fehler}\}\)
Das ergibt 2 Eingabe-Äquivalenzklassen:
- \(E_1 = \{x : x \neq 0\}\) (alle Nicht-Null-Eingaben)
- \(E_2 = \{x : x = 0\}\) (Null)
Feine Partition (3 Ausgabekategorien - was wir gewählt haben):
- \(C_1 = \{y : y > 0\}\) (positive Ausgaben)
- \(C_2 = \{y : y < 0\}\) (negative Ausgaben)
- \(C_3 = \{\text{Fehler}\}\)
Das ergibt 3 Eingabe-Äquivalenzklassen:
- \(E_1 = \{x : x > 0\}\) (positive Eingaben)
- \(E_2 = \{x : x < 0\}\) (negative Eingaben)
- \(E_3 = \{x : x = 0\}\) (Null)
Sehr feine Partition (5 Ausgabekategorien - übertrieben):
- \(C_1 = \{y : y > 1\}\) (Ausgabe größer als 1)
- \(C_2 = \{y : 0 < y \leq 1\}\) (Ausgabe zwischen 0 und 1)
- \(C_3 = \{y : -1 \leq y < 0\}\) (Ausgabe zwischen -1 und 0)
- \(C_4 = \{y : y < -1\}\) (Ausgabe kleiner als -1)
- \(C_5 = \{\text{Fehler}\}\)
Das ergibt 5 Eingabe-Äquivalenzklassen:
- \(E_1 = \{x : 0 < x < 1\}\) (Eingaben zwischen 0 und 1)
- \(E_2 = \{x : x \geq 1\}\) (Eingaben ≥ 1)
- \(E_3 = \{x : -1 \leq x < 0\}\) (Eingaben zwischen -1 und 0)
- \(E_4 = \{x : x < -1\}\) (Eingaben < -1)
- \(E_5 = \{x : x = 0\}\) (Null)
Alle drei sind mathematisch gültig! Aber welche ist am besten fürs Testen?
2. Kompromiss: Granularität vs. Praktikabilität
| Partitions-Wahl | # Tests | Vorteile | Nachteile |
|---|---|---|---|
| Grob (2) | 2 Tests | Schnell, minimal | Könnte Vorzeichen-Bugs übersehen |
| Fein (3) | 3 Tests | Gutes Gleichgewicht, fängt Vorzeichen-Bugs | Noch praktikabel |
| Sehr fein (5) | 5 Tests | Maximale Abdeckung | Übertrieben für einfache Funktion, abnehmender Nutzen |
Wir haben die feine Partition (3 Kategorien) gewählt, weil:
- ✅ Trennung von positiv/negativ fängt Vorzeichen-Bugs (häufig in Mathe-Funktionen)
- ✅ Erfordert nur 3 Tests (praktikabel)
- ✅ Passt zu typischen Verhaltenskategorien für Kehrwert-Funktionen
- ❌ Die grobe Partition (2 Kategorien) übersieht potenzielle Vorzeichen-Bugs
- ❌ Die sehr feine Partition (5 Kategorien) fügt Tests ohne viel Extra-Wert hinzu
3. Richtlinien zur Wahl der Ausgabekategorien
Wählen Sie Ihre Partition basierend auf:
| Überlegung | Zu stellende Frage | Beispiel |
|---|---|---|
| Code-Pfade | Verzweigt der Code basierend auf dieser Ausgabekategorie? | Wenn if result > 0: ... existiert, sind positiv/negativ wichtig |
| Mathematische Eigenschaften | Hat dieser Ausgabewert besondere Bedeutung? | Null, Unendlich, spezielle Konstanten |
| Domänen-Bedeutung | Bedeuten verschiedene Ausgabebereiche verschiedene Dinge für Nutzer? | In Ray-Tracing sind None vs. Koordinaten fundamental unterschiedlich |
| Bug-Risiko | Wo sind Bugs am wahrscheinlichsten? | Vorzeichen-Fehler sind häufig → Trenne positiv/negativ |
| Praktisches Limit | Wie viele Tests können Sie warten? | 3-5 Klassen pro Dimension sind meist genug |
4. Die wichtige Einsicht: Sie kontrollieren die Granularität
Die mathematische Definition schreibt keine spezifische Partition vor. Sie erfordert nur:
\[C_1 \cup C_2 \cup \cdots \cup C_n = \text{(gesamter Ausgabebereich)}\] \[C_i \cap C_j = \emptyset \quad \text{für } i \neq j\]Sie wählen, wie Sie den Ausgaberaum aufteilen. Verschiedene Aufteilung → verschiedene Äquivalenzklassen → verschiedene Tests.
Fazit: Beginnen Sie mit 3-4 Ausgabekategorien basierend auf Code-Verhalten und mathematischer Bedeutung. Verfeinern Sie, wenn Sie Bugs finden, die nicht gefangen wurden.
1.1.3 White-Box vs. Black-Box: Woher wissen wir, wo partitioniert werden soll?
Wichtige Klarstellung: Der Ansatz, den wir hier verwenden, ist White-Box-Testing - wir können die Implementierung sehen.
Warum ist das wichtig?
Betrachte reciprocal_sum(x, y, z). Woher wissen wir, dass wir basierend auf \(x+y+z\) partitionieren sollen?
Weil wir den Code sehen können:
def reciprocal_sum(x: float, y: float, z: float) -> float:
total = x + y + z # ← DAS sagt uns, auf der Summe zu partitionieren!
if abs(total) < 1e-10:
raise ZeroDivisionError("Sum is too close to zero")
return 1.0 / total
Die Implementierung offenbart:
- Die Funktion berechnet
x + y + z(also ist die Summe wichtig, nicht einzelne Werte) - Sie gibt
1/totalzurück (also ist das Vorzeichen von total wichtig: positiv/negativ) - Sie prüft
abs(total) < 1e-10(also ist nahe-Null speziell)
Das sagt uns sofort die 3 Ausgabekategorien: positiv, negativ, Fehler.
Ohne den Code zu sehen (Black-Box-Testing):
Wenn wir nur die Funktionssignatur hätten:
def reciprocal_sum(x: float, y: float, z: float) -> float:
"""Return the reciprocal of the sum of x, y, and z."""
Müssten wir Partitionen erraten basierend auf:
- Funktionsname: “reciprocal_sum” deutet an, dass zuerst summiert wird
- Docstring: bestätigt, dass es
1/(x+y+z)ist - Mathematische Überlegung: Kehrwert versagt bei Null
Aber White-Box ist einfacher und präziser - Sie sehen genau, was der Code macht!
Für diese Vorlesung: Alle Beispiele sind White-Box - wir schauen auf den Code, um Partitionen zu finden. Das ist:
- ✅ Praktisch: Sie schreiben den Code, Sie sehen die Implementierung
- ✅ Präzise: Sie wissen genau, welche Verzweigungen existieren
- ✅ Realistisch: Die meisten Unit-Tests in echten Projekten sind White-Box
Wann nutzt man Black-Box? Beim Testen externer Bibliotheken/APIs, bei denen Sie keinen Quellcode haben. Das ist fortgeschrittener.
Dieser Abschnitt demonstriert:
- Einfache Funktionen → Leicht Äquivalenzklassen zu finden
- Mehrere Parameter → Klassen multiplizieren sich schnell
- Array-Eingaben → Strukturelle UND Wert-Klassen
- Komplexe Funktionen → Selbst KI-Assistenten haben Schwierigkeiten
Lass uns Intuition mit progressiven Beispielen aufbauen, von trivial bis realistisch.
1.1.4 Einfaches Float-Beispiel: reciprocal(x) = 1/x
Funktionsdefinition:
def reciprocal(x: float) -> float:
"""Return the reciprocal of x (1/x)."""
if x == 0:
raise ZeroDivisionError("Cannot divide by zero")
return 1.0 / x
Frage: Was sind die Äquivalenzklassen für Parameter x?
Intuitiver Ansatz (White-Box-Testing):
Da wir die Implementierung sehen können, identifizieren wir Spezialfälle natürlich:
Beim Betrachten des Codes fällt uns sofort auf:
-
x = 0ist speziell - Der Code prüft explizit darauf mitif x == 0und wirft einen Fehler. Das ist eindeutig eine andere Verhaltenskategorie! - Positiv vs. Negativ zählt - Für die Kehrwert-Funktion
1/x:- Wenn
x > 0(wiex = 5.0), erhalten wir ein positives Ergebnis (1/5 = 0.2) - Wenn
x < 0(wiex = -5.0), erhalten wir ein negatives Ergebnis (1/(-5) = -0.2) - Das Vorzeichen der Eingabe bestimmt das Vorzeichen der Ausgabe!
- Wenn
- Das sind unterschiedliche Verhalten - Die Funktion verhält sich grundlegend anders bei positiven, negativen und Null-Eingaben.
Also identifizieren wir natürlich 3 Äquivalenzklassen:
| Äquivalenzklasse | Beschreibung | Repräsentativer Wert | Erwartetes Verhalten |
|---|---|---|---|
| Positive Zahlen | x > 0 |
x = 5.0 |
Gibt positiven Kehrwert zurück (0.2) |
| Negative Zahlen | x < 0 |
x = -5.0 |
Gibt negativen Kehrwert zurück (-0.2) |
| Null | x == 0 |
x = 0.0 |
Wirft ZeroDivisionError |
Warum diese drei Klassen?
Diese Partitionierung kommt direkt aus dem Verständnis des Codes:
- Null ist speziell - Sie löst den Fehlerbehandlungs-Zweig aus (
if x == 0) - Vorzeichen zählt - Positive und negative Eingaben folgen demselben Code-Pfad (
return 1.0 / x), produzieren aber Ausgaben mit verschiedenen Vorzeichen - Alle Eingaben sind abgedeckt - Jeder mögliche Float ist entweder positiv, negativ oder null
Test-Code:
import pytest
def test_reciprocal_positive_number():
"""Equivalence class: Positive numbers (x > 0)"""
result = reciprocal(5.0)
assert result == pytest.approx(0.2, rel=1e-10)
def test_reciprocal_negative_number():
"""Equivalence class: Negative numbers (x < 0)"""
result = reciprocal(-5.0)
assert result == pytest.approx(-0.2, rel=1e-10)
def test_reciprocal_zero():
"""Equivalence class: Zero (x == 0)"""
with pytest.raises(ZeroDivisionError):
reciprocal(0.0)
Für die Neugierigen: Mathematische Formalisierung
Der intuitive Ansatz oben kann mit der mathematischen Definition aus Abschnitt 5.7 formalisiert werden. So geht’s:
-
Definiere die Funktion: \(f(x) = \frac{1}{x}\) mit Definitionsbereich \(D = \mathbb{R}\)
- Partitioniere den Ausgabebereich in Kategorien:
- \(C_1 = \{y : y > 0\}\) (positive Ausgaben)
- \(C_2 = \{y : y < 0\}\) (negative Ausgaben)
- \(C_3 = \{\text{Fehler}\}\) (Division durch Null)
-
Die Äquivalenzrelation: Zwei Eingaben \(x_1 \sim x_2\) wenn \(f(x_1)\) und \(f(x_2)\) zur gleichen Ausgabekategorie \(C_i\) gehören
- Die induzierten Eingabe-Äquivalenzklassen:
- \(E_1 = \{x \in \mathbb{R} : f(x) \in C_1\} = \{x : x > 0\}\) (positive Eingaben → positive Ausgaben)
- \(E_2 = \{x \in \mathbb{R} : f(x) \in C_2\} = \{x : x < 0\}\) (negative Eingaben → negative Ausgaben)
- \(E_3 = \{x \in \mathbb{R} : f(x) \in C_3\} = \{x : x = 0\}\) (Null → Fehler)
- Überprüfe die Partition:
- \(E_1 \cup E_2 \cup E_3 = \mathbb{R}\) ✅ (deckt alle reellen Zahlen ab)
- \(E_i \cap E_j = \emptyset\) für \(i \neq j\) ✅ (keine Überlappung)
Die mathematische Formalisierung bestätigt, was wir intuitiv entdeckt haben: die Ausgabekategorien (\(C_1, C_2, C_3\)) bestimmen direkt die Eingabe-Äquivalenzklassen (\(E_1, E_2, E_3\)).
Was ist mit nahe-Null und sehr großen Werten?
Sie fragen sich vielleicht: “Was ist mit x = 0.001 (nahe Null) oder x = 1e10 (sehr groß)?”
Diese gehören noch zur Äquivalenzklasse positive Zahlen - sie folgen demselben Code-Pfad und produzieren dieselbe Verhaltenskategorie (positive Ausgabe). Jedoch repräsentieren sie Grenzwerte, die numerische Präzisionsprobleme oder Extremverhalten aufdecken könnten:
- Nahe Null (x = 0.001): Gibt sehr großen Wert zurück (1000.0) - testet Fließkomma-Grenzen
- Sehr groß (x = 1e10): Gibt sehr kleinen Wert zurück (1e-10) - testet Underflow-Verhalten
Diese Grenzwerte sind wichtig, gehören aber zu einer anderen Test-Technik - wir werden Boundary Value Analysis in der nächsten Vorlesung behandeln. Erkenne für jetzt:
- Äquivalenzklassen partitionieren Eingaben nach Verhalten
- Grenzwerte testen die Ränder dieser Partitionen
Wichtige Einsicht: Selbst eine einfache Ein-Parameter-Funktion hat 3 Kern-Äquivalenzklassen. Durch Testen eines Repräsentanten aus jeder Klasse erreichen wir hohes Vertrauen ohne erschöpfendes Testen.
1.1.5 Mehrere Parameter: reciprocal_sum(x, y, z) = 1/(x+y+z)
Funktionsdefinition:
def reciprocal_sum(x: float, y: float, z: float) -> float:
"""Return the reciprocal of the sum of x, y, and z."""
total = x + y + z
if abs(total) < 1e-10:
raise ZeroDivisionError("Sum is too close to zero")
return 1.0 / total
Frage: Was sind jetzt die Äquivalenzklassen?
Intuitiver Ansatz (White-Box-Testing):
Jetzt haben wir 3 Parameter! Aber schauen wir auf den Code, um zu verstehen, was wichtig ist:
Beim Betrachten des Codes fällt uns sofort auf:
-
Die Funktion berechnet
total = x + y + z- Das sagt uns, dass die Summe wichtig ist, nicht die einzelnen Werte vonx,yoderz! -
Nahe-Null-Summe ist speziell - Der Code prüft
if abs(total) < 1e-10und wirft einen Fehler. Das ist eine spezielle Verhaltenskategorie. - Vorzeichen der Summe zählt - Die Funktion gibt
1.0 / totalzurück:- Wenn
total > 0(wie1.0 + 2.0 + 3.0 = 6.0), erhalten wir ein positives Ergebnis (1/6 ≈ 0.167) - Wenn
total < 0(wie-1.0 + (-2.0) + (-3.0) = -6.0), erhalten wir ein negatives Ergebnis (-1/6 ≈ -0.167)
- Wenn
- Individuelle Parameter-Vorzeichen sind egal - Solange die Summe gleich ist!
(1.0, 2.0, 3.0)→ Summe = 6 → positive Ausgabe(100.0, -50.0, -44.0)→ Summe = 6 → gleiche positive Ausgabe- Beide sind in der gleichen Äquivalenzklasse, weil sie dieselbe Summe haben!
Also identifizieren wir natürlich 3 Äquivalenzklassen (wie zuvor!):
| Äquivalenzklasse | Beschreibung | Repräsentative Werte | Erwartetes Verhalten |
|---|---|---|---|
| Positive Summe | x+y+z > 0 |
(1.0, 2.0, 3.0) → Summe=6 |
Gibt positiven Kehrwert zurück (≈0.167) |
| Negative Summe | x+y+z < 0 |
(-1.0, -2.0, -3.0) → Summe=-6 |
Gibt negativen Kehrwert zurück (≈-0.167) |
| Null-Summe | |x+y+z| < 1e-10 |
(1.0, -0.5, -0.5) → Summe≈0 |
Wirft ZeroDivisionError |
Wichtige Einsicht: Obwohl wir 3 Eingabe-Parameter haben, haben wir nur 3 Äquivalenzklassen! Warum? Weil das Verhalten der Funktion nur von der Summe abhängt, nicht von einzelnen Parameterwerten.
Warum diese drei Klassen?
Diese Partitionierung kommt direkt aus dem Verständnis des Codes:
- Die Summe wird zuerst berechnet - Die Zeile
total = x + y + zsagt uns, dass einzelne Werte nicht zählen, nur ihre Summe - Null-Summe ist speziell - Sie löst den Fehlerbehandlungs-Zweig aus (
if abs(total) < 1e-10) - Vorzeichen der Summe zählt - Positive und negative Summen folgen demselben Code-Pfad (
return 1.0 / total), produzieren aber Ausgaben mit verschiedenen Vorzeichen - Alle Eingabe-Kombinationen sind abgedeckt - Jedes mögliche Tripel
(x, y, z)produziert eine Summe, die entweder positiv, negativ oder nahe-Null ist
Test-Code:
import pytest
def test_reciprocal_sum_positive_total():
"""Equivalence class: Positive sum (x+y+z > 0)"""
result = reciprocal_sum(1.0, 2.0, 3.0) # sum = 6
assert result == pytest.approx(1.0 / 6.0, rel=1e-10)
def test_reciprocal_sum_negative_total():
"""Equivalence class: Negative sum (x+y+z < 0)"""
result = reciprocal_sum(-1.0, -2.0, -3.0) # sum = -6
assert result == pytest.approx(-1.0 / 6.0, rel=1e-10)
def test_reciprocal_sum_zero_total():
"""Equivalence class: Zero sum (x+y+z ≈ 0)"""
with pytest.raises(ZeroDivisionError):
reciprocal_sum(1.0, -0.5, -0.5) # sum = 0.0
Für die Neugierigen: Mathematische Formalisierung
Der intuitive Ansatz oben kann mit der mathematischen Definition aus Abschnitt 5.7 formalisiert werden. So geht’s:
-
Definiere die Funktion: \(f(x, y, z) = \frac{1}{x+y+z}\) mit Definitionsbereich \(D = \mathbb{R}^3\) (3-dimensionaler Eingaberaum)
- Partitioniere den Ausgabebereich in Kategorien:
- \(C_1 = \{w : w > 0\}\) (positive Ausgaben)
- \(C_2 = \{w : w < 0\}\) (negative Ausgaben)
- \(C_3 = \{\text{Fehler}\}\) (Summe zu nahe bei Null)
-
Die Äquivalenzrelation: Zwei Eingabetripel \((x_1, y_1, z_1) \sim (x_2, y_2, z_2)\) wenn ihre Ausgaben zur gleichen Kategorie gehören
- Die induzierten Eingabe-Äquivalenzklassen in \(\mathbb{R}^3\):
- \(E_1 = \{(x,y,z) \in \mathbb{R}^3 : x+y+z > 0\}\) (positive Summe → positive Ausgabe)
- \(E_2 = \{(x,y,z) \in \mathbb{R}^3 : x+y+z < 0\}\) (negative Summe → negative Ausgabe)
- \(E_3 = \{(x,y,z) \in \mathbb{R}^3 : \lvert x+y+z \rvert < 10^{-10}\}\) (nahe-Null-Summe → Fehler)
- Überprüfe die Partition:
- \(E_1 \cup E_2 \cup E_3 = \mathbb{R}^3\) ✅ (deckt alle Eingabetripel ab)
- \(E_i \cap E_j = \emptyset\) für \(i \neq j\) ✅ (keine Überlappung)
Wichtige mathematische Einsicht:
Die Tripel (1.0, 2.0, 3.0) und (100.0, -50.0, -44.0) sind in der gleichen Äquivalenzklasse \(E_1\), weil:
Beide erfüllen \(x+y+z = 6 > 0\), also gehören beide zu \(E_1 = \{(x,y,z) : x+y+z > 0\}\).
Sie produzieren Ausgaben in derselben Kategorie (\(C_1\) = positiv), obwohl individuelle Parameterwerte wildly unterschiedlich sind! Das ist die Kraft der Äquivalenzrelation - sie gruppiert Eingaben nach ihrem Verhaltens-Ergebnis, nicht nach ihren individuellen Werten.
Was ist mit gemischten Vorzeichen oder nahe-Null-Summen?
Sie fragen sich vielleicht: “Was ist mit Eingaben wie (1.0, 2.0, -0.5) (gemischte Vorzeichen) oder (1.0, -0.999, 0.0) (nahe-Null-Summe)?”
- Gemischte Vorzeichen
(1.0, 2.0, -0.5): Summe = 2.5 → Noch in der positiven Summen-Äquivalenzklasse - Nahe-Null-Summe
(1.0, -0.999, 0.0): Summe = 0.001 → Noch in der positiven Summen-Äquivalenzklasse (aber testet Grenzverhalten)
Die Vorzeichen-Kombinationen (alle positiv, alle negativ, gemischt) sind nur verschiedene Wege, dieselbe Summen-Kategorie zu erreichen. Sie sind keine separaten Äquivalenzklassen!
Nahe-Null-Summen wie 0.001 testen Grenzverhalten (werden in der nächsten Vorlesung behandelt), gehören aber noch zu den positiven/negativen Äquivalenzklassen.
Wichtige Einsicht: Selbst mit 3 Parametern haben wir nur 3 Kern-Äquivalenzklassen. Die Anzahl der Wege, jede Klasse zu erreichen, steigt (z.B. viele Vorzeichen-Kombinationen produzieren positive Summe), aber die Verhaltenskategorien bleiben gleich.
1.1.6 Winkel-basiertes Beispiel: calculate_ray_slope(angle_degrees)
Bevor wir komplexe Array-Funktionen angehen, analysieren wir eine Funktion, die aus Ihrem Road Profile Viewer extrahiert wurde und Winkelberechnungen behandelt. Das führt ein neues Konzept ein: Funktionen, die verschiedene Typen zurückgeben (float oder None).
Funktionsdefinition:
Diese Funktion ist aus find_intersection() extrahiert - sie berechnet die Steigung eines Kamera-Strahls basierend auf seinem Winkel:
import numpy as np
def calculate_ray_slope(angle_degrees: float) -> float | None:
"""
Calculate the slope of a ray given its angle in degrees.
Returns None for vertical angles (±90°) because vertical lines have undefined slope.
Parameters:
-----------
angle_degrees : float
Angle in degrees (positive = upward, negative = downward, 0 = horizontal)
Returns:
--------
float | None
Slope of the ray (rise/run), or None if angle is vertical
"""
angle_rad = -np.deg2rad(angle_degrees) # Convert to radians, negate for coordinate system
# Handle vertical ray (cos(90°) = 0, so cos(angle) ≈ 0 means vertical)
if np.abs(np.cos(angle_rad)) < 1e-10:
return None
slope = np.tan(angle_rad)
return slope
Frage: Was sind die Äquivalenzklassen für angle_degrees?
Intuitiver Ansatz (White-Box-Testing):
Diese Funktion ist interessanter - sie gibt verschiedene Typen zurück (float oder None). Schauen wir auf den Code:
Beim Betrachten des Codes fällt uns sofort auf:
-
Vertikale Winkel sind speziell - Der Code prüft
if np.abs(np.cos(angle_rad)) < 1e-10und gibtNonezurück. Das behandelt den Fall, wo ±90°-Winkel vertikale Strahlen mit undefinierter Steigung produzieren. - Die Funktion berechnet
slope = np.tan(angle_rad)- Für nicht-vertikale Winkel berechnet sie den Tangens:- Negative Winkel (wie -45°): Abwärts-Strahlen → negative Steigungen
- Null-Winkel (0°): Horizontaler Strahl → Null-Steigung
- Positive Winkel (wie 45°): Aufwärts-Strahlen → positive Steigungen
-
Das Vorzeichen des Winkels bestimmt das Vorzeichen der Steigung - Genau wie bei Kehrwerten!
- Es gibt 4 unterschiedliche Verhalten - Im Unterschied zu vorherigen Beispielen mit 3 Klassen hat diese Funktion:
- Abwärts-Strahlen (negative Steigung)
- Horizontaler Strahl (Null-Steigung)
- Aufwärts-Strahlen (positive Steigung)
- Vertikale Strahlen (None - undefinierte Steigung)
Also identifizieren wir natürlich 4 Äquivalenzklassen:
| Äquivalenzklasse | Beschreibung | Repräsentativer Wert | Erwartetes Verhalten |
|---|---|---|---|
| Abwärts-Winkel | -90° < angle < 0° |
angle = -45° |
Gibt negative Steigung zurück (tan(-45°) = -1.0) |
| Horizontal | angle = 0° |
angle = 0° |
Gibt Null-Steigung zurück (tan(0°) = 0.0) |
| Aufwärts-Winkel | 0° < angle < 90° |
angle = 45° |
Gibt positive Steigung zurück (tan(45°) = 1.0) |
| Vertikale Winkel | angle = ±90° |
angle = 90° oder -90° |
Gibt None zurück (undefinierte Steigung) |
Warum diese vier Klassen?
Diese Partitionierung kommt direkt aus dem Verständnis des Codes und der Domäne:
- Vertikale Winkel sind speziell - Sie lösen die Spezialfall-Prüfung aus (
if np.abs(np.cos(angle_rad)) < 1e-10) und gebenNonezurück - Vorzeichen des Winkels zählt - Negative Winkel produzieren Abwärts-Strahlen (negative Steigungen), positive Winkel produzieren Aufwärts-Strahlen (positive Steigungen)
- Null ist unterschiedlich - Horizontaler Strahl (0°) produziert Null-Steigung, was mathematisch anders ist als positiv/negativ
- Alle Winkel sind abgedeckt - Jeder Winkel im praktischen Bereich [-90°, 90°] fällt in eine dieser vier Kategorien
Wichtige Beobachtung: Diese Funktion hat 4 Äquivalenzklassen (nicht 3 wie die vorherigen Beispiele), weil sie 4 unterschiedliche Ausgabeverhalten hat: negative Steigung, Null-Steigung, positive Steigung und None.
Test-Code:
import pytest
import numpy as np
def test_calculate_ray_slope_downward_angle():
"""Equivalence class: Downward angles (-90° < angle < 0°)"""
slope = calculate_ray_slope(-45.0)
assert slope is not None, "Downward angle should return a slope"
assert slope == pytest.approx(-1.0, rel=1e-9) # tan(-45°) = -1
def test_calculate_ray_slope_horizontal():
"""Equivalence class: Horizontal (angle = 0°)"""
slope = calculate_ray_slope(0.0)
assert slope == pytest.approx(0.0, abs=1e-10) # tan(0°) = 0
def test_calculate_ray_slope_upward_angle():
"""Equivalence class: Upward angles (0° < angle < 90°)"""
slope = calculate_ray_slope(45.0)
assert slope is not None, "Upward angle should return a slope"
assert slope == pytest.approx(1.0, rel=1e-9) # tan(45°) = 1
def test_calculate_ray_slope_vertical_upward():
"""Equivalence class: Vertical upward (angle = 90°)"""
slope = calculate_ray_slope(90.0)
assert slope is None, "Vertical angle should return None"
def test_calculate_ray_slope_vertical_downward():
"""Equivalence class: Vertical downward (angle = -90°)"""
slope = calculate_ray_slope(-90.0)
assert slope is None, "Vertical angle should return None"
Für die Neugierigen: Mathematische Formalisierung
Der intuitive Ansatz oben kann mit der mathematischen Definition aus Abschnitt 5.7 formalisiert werden. So geht’s:
- Definiere die Funktion: \(f(\theta) = \tan(-\theta \cdot \frac{\pi}{180})\) mit Definitionsbereich \(D = \mathbb{R}\) (Winkel in Grad)
- Gibt
Nonezurück wenn \(\lvert\cos(-\theta \cdot \frac{\pi}{180})\rvert < 10^{-10}\) (vertikale Winkel)
- Gibt
- Partitioniere den Ausgabebereich in Kategorien:
- \(C_1 = \{s : s < 0\}\) (negative Steigungen - Abwärts-Strahlen)
- \(C_2 = \{s : s = 0\}\) (Null-Steigung - horizontaler Strahl)
- \(C_3 = \{s : s > 0\}\) (positive Steigungen - Aufwärts-Strahlen)
- \(C_4 = \{\text{None}\}\) (undefiniert - vertikale Strahlen)
-
Die Äquivalenzrelation: Zwei Winkel \(\theta_1 \sim \theta_2\) wenn \(f(\theta_1)\) und \(f(\theta_2)\) zur gleichen Ausgabekategorie gehören
- Die induzierten Eingabe-Äquivalenzklassen:
- \(E_1 = \{\theta \in \mathbb{R} : -90° < \theta < 0°\}\) (Abwärts-Winkel → negative Steigungen)
- \(E_2 = \{\theta \in \mathbb{R} : \theta = 0°\}\) (horizontal → Null-Steigung)
- \(E_3 = \{\theta \in \mathbb{R} : 0° < \theta < 90°\}\) (Aufwärts-Winkel → positive Steigungen)
- \(E_4 = \{\theta \in \mathbb{R} : \theta = \pm 90°\}\) (vertikal → None)
- Überprüfe die Partition (für praktischen Winkelbereich \([-90°, 90°]\)):
- \(E_1 \cup E_2 \cup E_3 \cup E_4\) deckt alle Winkel ab ✅
- \(E_i \cap E_j = \emptyset\) für \(i \neq j\) ✅
Wichtige mathematische Einsicht:
Im Unterschied zu unseren vorherigen Beispielen mit 3 Klassen hat diese Funktion 4 Äquivalenzklassen, weil wir 4 Ausgabekategorien gewählt haben:
- Wir haben \(C_2 = \{0\}\) von \(C_1\) und \(C_3\) getrennt, weil Null geometrische Bedeutung hat (horizontal vs. angewinkelte Strahlen)
- Wir haben \(C_4 = \{\text{None}\}\) hinzugefügt, weil der Ausgabetyp wechselt (float vs. None)
Wir hätten nur 2 Kategorien wählen können (\(C_1 = \{\text{float}\}\), \(C_2 = \{\text{None}\}\)) für nur 2 Äquivalenzklassen, aber die feinere Partition fängt mehr potenzielle Bugs!
Was ist mit nahe-vertikalen Winkeln oder sehr steilen Steigungen?
Sie fragen sich vielleicht: “Was ist mit angle = 89.9° (nahe vertikal) oder angle = -0.1° (fast horizontal)?”
- Nahe vertikal (89.9°):
tan(89.9°) ≈ 573→ Noch in der Aufwärts-Winkel-Äquivalenzklasse (gibt positiven Float zurück) - Fast horizontal (-0.1°):
tan(-0.1°) ≈ -0.0017→ Noch in der Abwärts-Winkel-Äquivalenzklasse (gibt negativen Float zurück)
Das sind Grenzwerte, die Extremverhalten testen (sehr große Steigungen, sehr kleine Steigungen), aber sie gehören noch zu den Kern-Äquivalenzklassen basierend auf Ausgabekategorie.
Wichtige Einsicht: Diese Funktion hat 4 Kern-Äquivalenzklassen statt 3. Die Anzahl der Äquivalenzklassen hängt davon ab, wie viele unterschiedliche Verhaltenskategorien existieren, nicht von der Anzahl der Parameter. Hier haben wir: negativer Float, Null-Float, positiver Float und None.
1.1.7 Meta-Einsicht: Das gleiche Muster, unterschiedliche Granularität
Moment mal! Lass uns die Ausgabebereiche aller drei analysierten Funktionen vergleichen:
| Funktion | Mögliche Ausgaben | Gewählte Äquivalenzklassen |
|---|---|---|
reciprocal(x) |
Positiv, Negativ, Undefiniert (Fehler) | 3 Klassen: Positiv / Negativ / Fehler |
reciprocal_sum(x,y,z) |
Positiv, Negativ, Undefiniert (Fehler) | 3 Klassen: Positiv / Negativ / Fehler |
calculate_ray_slope(angle) |
Positiv, Null, Negativ, Undefiniert (None) | 4 Klassen: Positiv / Null / Negativ / Undefiniert |
Mustererkennung: Alle drei Funktionen produzieren Ausgaben aus dem gleichen mathematischen Raum:
Reelle Zahlen ∪ {undefiniert}
↓
Positiv / Null / Negativ / Undefiniert
Warum haben wir also 3 Klassen für die ersten beiden und 4 für die dritte gewählt?
Die Antwort: Praktische Bedeutung von Null
reciprocal(x): Die Ausgabe kann mathematisch nicht Null sein (1/x ≠ 0 für jedes reelle x)- Null existiert nicht im Ausgabebereich
- Wir haben: positiv, negativ, Fehler
reciprocal_sum(x,y,z): Die Ausgabe kann mathematisch nicht Null sein (1/sum ≠ 0 für jede Nicht-Null-Summe)- Null existiert nicht im Ausgabebereich
- Wir haben: positiv, negativ, Fehler
calculate_ray_slope(angle): Die Ausgabe kann Null sein (tan(0°) = 0)- Null existiert im Ausgabebereich
- Wir haben uns entschieden, sie als speziell zu behandeln, weil horizontale Strahlen (Steigung = 0) kritische geometrische Bedeutung im Raytracing haben
- Null ist die Grenze zwischen Aufwärts- und Abwärtssteigungen
Die Schlüsselentscheidung: Granularität ist eine Wahl
Wir hätten calculate_ray_slope mit nur 3 Klassen behandeln können:
# Gröbere Granularität (3 Klassen):
1. Nicht-vertikal, Nicht-Null-Steigung (-90° < angle < 0° und 0° < angle < 90°)
2. Horizontal (angle = 0°)
3. Vertikal (angle = ±90°)
# ODER noch gröber (2 Klassen):
1. Gültige Winkel (alle Winkel außer ±90°)
2. Ungültige Winkel (±90°)
Warum wir feinere Granularität gewählt haben (4 Klassen):
- Geometrische Bedeutung: Horizontale Strahlen verhalten sich grundlegend anders als angewinkelte Strahlen
- Vorzeichen-Testen: Das Trennen von positiven/negativen Steigungen fängt Trigonometrie-Bugs (falsches Vorzeichen in Berechnungen)
- Null-Grenze: Das Testen von
tan(0°) = 0.0exakt verifiziert den Übergangspunkt - Reale Verwendung: In der tatsächlichen
find_intersection()-Funktion folgen horizontale vs. Abwärts- vs. Aufwärts-Strahlen unterschiedlichen Logikpfaden
Allgemeines Prinzip: Wähle Granularität basierend auf
- Mathematischen Eigenschaften: Hat der Ausgabewert eine spezielle Bedeutung? (z.B. Null, Unendlich, spezielle Konstanten)
- Domänenbedeutung: Verhält sich diese Ausgabekategorie in deiner Anwendung anders?
- Bug-Risiko: Sind Bugs wahrscheinlicher an Übergängen zwischen Kategorien?
- Code-Pfade: Behandelt der Code unterschiedliche Ausgabebereiche unterschiedlich?
Beide Ansätze sind gültig! Die formale Definition von Äquivalenzklassen schreibt keine spezifische Granularität vor - sie erfordert nur:
- Disjunkte Partitionen (keine Überlappung)
- Vollständige Abdeckung (alle Eingaben klassifiziert)
- Repräsentatives Testen (ein Test pro Klasse)
Sie entscheiden, wie fein oder grob die Partitionierung sein soll, basierend darauf, was für Ihre Testing-Ziele wichtig ist.
Fazit: Äquivalenzklassen-Analyse ist sowohl Kunst als auch Wissenschaft. Die Wissenschaft sind die formalen Partitionierungsregeln. Die Kunst ist die Wahl des richtigen Detailgrads für Ihren Kontext.
1.1.8 Diskrete/Endlich-wertige Funktionen: Wenn Ausgaben abzählbar sind
Gute Nachricht! Alle bisherigen Beispiele (reciprocal, reciprocal_sum, calculate_ray_slope) haben kontinuierliche Ausgabebereiche - sie geben Fließkommazahlen aus einer unendlichen Menge zurück (ℝ oder ℝ ∪ {None}). Das bedeutet, wir mussten wählen, wie wir den Ausgaberaum partitionieren (3 Kategorien? 4? 5?).
Aber was ist mit Funktionen, die diskrete Werte zurückgeben - endliche Mengen wie {"A", "B", "C", "D", "F"} oder {True, False} oder Statuscodes?
Die Vereinfachung: Wenn Funktionen diskrete/endlich-wertige Ausgaben haben, wird das Finden von Äquivalenzklassen viel einfacher! Die Ausgabekategorien sind bereits definiert durch den Rückgabetyp der Funktion - keine Designentscheidung nötig!
Kontrast:
| Funktionstyp | Ausgabebereich | Äquivalenzklassen-Herausforderung | Beispiel |
|---|---|---|---|
| Kontinuierlich reell-wertig | Unendlich (ℝ) | Muss wählen, wie Ausgaben partitioniert werden | reciprocal(x): wählte {positiv, negativ, Fehler} |
| Diskret/endlich-wertig | Endliche Menge | Ausgabekategorien vordefiniert! | calculate_grade(score): {"A", "B", "C", "D", "F", Fehler} ← nur 6 Klassen |
Die Verschiebung der Kernfrage:
- Kontinuierliche Funktionen: “Wie soll ich den unendlichen Ausgaberaum partitionieren?” (Designentscheidung)
- Diskrete Funktionen: “Welche Eingaben erzeugen welche Ausgabe?” (Analyseaufgabe)
Aber täuschen Sie sich nicht - die Herausforderung verschwindet nicht! Sie müssen trotzdem analysieren:
- Welche Eingaben bilden auf welche Ausgaben ab? (erfordert Verständnis des Codes)
- Gibt es Grenzwerte zwischen Kategorien? (z.B. score = 89 vs 90)
- Was ist mit ungültigen Eingaben? (z.B. score = -10 oder score = 150)
Schauen wir uns das in Aktion mit progressiv komplexeren Beispielen an:
- Einfache diskrete Ausgaben: Buchstabennoten (5 gültige Ausgaben + 1 Fehler)
- Tupel/zusammengesetzte Rückgaben: Passwortvalidierung (Boolean × mehrere Fehlertypen)
- Hybrid diskret: Kontinuierliche Eingaben, die auf diskrete Kostenkategorien abbilden
Für die Neugierigen: Mathematische Formalisierung diskreter Funktionen
Gegeben eine diskrete Funktion:
\[g: D \rightarrow \{o_1, o_2, \ldots, o_k\}\]wobei \(o_1, o_2, \ldots, o_k\) die endlich vielen möglichen Ausgabewerte sind (z.B. {"A", "B", "C", "D", "F"} für Noten).
Schritt 1: Ausgabekategorien sind bereits definiert
Anders als bei kontinuierlichen Funktionen, wo wir wählten, wie ℝ partitioniert wird, sind hier die Ausgabekategorien gegeben:
\[C_i = \{o_i\} \quad \text{für } i = 1, 2, \ldots, k\]Jede Ausgabekategorie ist eine Singleton-Menge, die genau einen möglichen Ausgabewert enthält.
Schritt 2: Äquivalenzrelation (wie zuvor)
Zwei Eingaben \(x_1, x_2 \in D\) sind äquivalent, wenn:
\[x_1 \sim x_2 \iff g(x_1) = g(x_2)\]Das heißt, sie erzeugen den gleichen Ausgabewert.
Schritt 3: Induzierte Eingabe-Äquivalenzklassen
\[E_i = \{x \in D : g(x) = o_i\}\]Die \(i\)-te Äquivalenzklasse enthält alle Eingaben, die Ausgabe \(o_i\) erzeugen.
Schritt 4: Schlüsseleigenschaften
-
Anzahl der Klassen gleich Anzahl der Ausgaben: \(\text{Anzahl der Äquivalenzklassen} = k\) (Keine Wahl involviert - wird durch den Rückgabetyp der Funktion bestimmt!)
- Partitionseigenschaften (weiterhin erforderlich):
- Disjunkt: \(E_i \cap E_j = \emptyset\) für \(i \neq j\) (keine Eingabe erzeugt zwei verschiedene Ausgaben)
- Vollständig: \(E_1 \cup E_2 \cup \cdots \cup E_k = D\) (jede gültige Eingabe erzeugt irgendeine Ausgabe)
- Komplexität verlagert sich zur Eingabeanalyse:
- Kontinuierlich: “Wie Ausgaben partitionieren?” → Designproblem
- Diskret: “Welche Eingaben erzeugen \(o_i\)?” → Analyseproblem
Beispiel: Noten-Funktion
\[g: [0, 100] \rightarrow \{\text{"A"}, \text{"B"}, \text{"C"}, \text{"D"}, \text{"F"}\}\]- Ausgabekategorien (gegeben): \(C_1 = {\text{“A”}}, C_2 = {\text{“B”}}, \ldots, C_5 = {\text{“F”}}\)
- Anzahl der Klassen: Genau 5 (keine Wahl!)
- Eingabeklassen: \(E_1 = [90, 100], E_2 = [80, 90), E_3 = [70, 80), E_4 = [60, 70), E_5 = [0, 60)\)
Die mathematische Struktur ist einfacher - Ausgabekategorien sind vorbestimmt. Aber Eingabeanalyse ist weiterhin erforderlich - Sie müssen den Code verstehen, um zu bestimmen, welche Eingaben welche Ausgaben erzeugen!
Beispiel 1: Einfache diskrete Ausgabe - calculate_grade(score)
Funktionsdefinition:
def calculate_grade(score: int) -> str:
"""
Berechne Buchstabennote basierend auf Punktzahl.
Args:
score: Ganzzahl zwischen 0 und 100
Returns:
Buchstabennote (A, B, C, D, F)
Raises:
ValueError: Wenn score nicht im gültigen Bereich liegt
"""
if score < 0 or score > 100:
raise ValueError("Score must be between 0 and 100")
if score >= 90:
return "A"
elif score >= 80:
return "B"
elif score >= 70:
return "C"
elif score >= 60:
return "D"
else:
return "F"
Frage: Was sind die Äquivalenzklassen für score?
Intuitiver Ansatz (White-Box-Testing):
Dies ist unsere erste diskrete Ausgabefunktion! Schauen wir uns an, was sie anders macht:
Beim Betrachten des Codes bemerken wir sofort:
-
Endliche Ausgabemenge - Die Funktion kann nur 5 mögliche Strings zurückgeben:
"A","B","C","D","F"(plusValueErrorfür ungültige Eingaben) -
Keine Wahl bei Ausgabekategorien - Anders als bei
reciprocal(x), wo wir wählten, ℝ in {positiv, negativ} zu partitionieren, sind hier die Kategorien gegeben: die 5 Buchstabennoten! - Klare Schwellwertgrenzen - Der Code hat explizite Vergleiche:
score >= 90→ “A”score >= 80→ “B”score >= 70→ “C”score >= 60→ “D”score < 60→ “F”
- Behandlung ungültiger Eingaben - Die Prüfung
if score < 0 or score > 100erzeugt eine 6. Äquivalenzklasse für Fehler
Also identifizieren wir natürlich 6 Äquivalenzklassen:
| Äquivalenzklasse | Beschreibung | Repräsentativer Wert | Erwartetes Verhalten |
|---|---|---|---|
| Note A | 90 ≤ score ≤ 100 |
score = 95 |
Gibt "A" zurück |
| Note B | 80 ≤ score < 90 |
score = 85 |
Gibt "B" zurück |
| Note C | 70 ≤ score < 80 |
score = 75 |
Gibt "C" zurück |
| Note D | 60 ≤ score < 70 |
score = 65 |
Gibt "D" zurück |
| Note F | 0 ≤ score < 60 |
score = 30 |
Gibt "F" zurück |
| Ungültige Punktzahl | score < 0 oder score > 100 |
score = -10 oder 150 |
Wirft ValueError |
Warum diese sechs Klassen?
-
Ausgabekategorien sind vorbestimmt - Die Funktionssignatur sagt uns, sie gibt
strzurück, und der Code zeigt genau 5 mögliche Werte: “A”, “B”, “C”, “D”, “F” -
Jede Ausgabe bildet auf einen kontinuierlichen Eingabebereich ab - Anders als bei kontinuierlichen Funktionen, wo wir Granularität wählen, sind hier die Schwellwerte (90, 80, 70, 60) fest im Code codiert
-
Fehlerkategorie ist explizit - Die Prüfung
if score < 0 or score > 100erzeugt eine 6. Klasse -
Grenzwerte sind kritisch - Punktzahlen wie 89, 90, 79, 80 usw. befinden sich an Partitionsgrenzen und verdienen besondere Aufmerksamkeit (dies behandeln wir in der Grenzwertanalyse)
Kernerkenn tnis: Wir haben 6 Klassen (5 gültige Noten + 1 Fehler), weil die Funktion 6 verschiedene Ausgabeverhalten hat. Keine Designentscheidung - wird durch den Code bestimmt!
Test-Code:
import pytest
def test_calculate_grade_A():
"""Äquivalenzklasse: Note A (90-100)"""
assert calculate_grade(95) == "A"
assert calculate_grade(90) == "A" # Grenzwert
assert calculate_grade(100) == "A" # Grenzwert
def test_calculate_grade_B():
"""Äquivalenzklasse: Note B (80-89)"""
assert calculate_grade(85) == "B"
assert calculate_grade(80) == "B" # Grenzwert
assert calculate_grade(89) == "B" # Grenzwert
def test_calculate_grade_C():
"""Äquivalenzklasse: Note C (70-79)"""
assert calculate_grade(75) == "C"
assert calculate_grade(70) == "C" # Grenzwert
assert calculate_grade(79) == "C" # Grenzwert
def test_calculate_grade_D():
"""Äquivalenzklasse: Note D (60-69)"""
assert calculate_grade(65) == "D"
assert calculate_grade(60) == "D" # Grenzwert
assert calculate_grade(69) == "D" # Grenzwert
def test_calculate_grade_F():
"""Äquivalenzklasse: Note F (0-59)"""
assert calculate_grade(30) == "F"
assert calculate_grade(0) == "F" # Grenzwert
assert calculate_grade(59) == "F" # Grenzwert
def test_calculate_grade_invalid_negative():
"""Äquivalenzklasse: Ungültige Punktzahl (< 0)"""
with pytest.raises(ValueError, match="Score must be between 0 and 100"):
calculate_grade(-10)
def test_calculate_grade_invalid_too_high():
"""Äquivalenzklasse: Ungültige Punktzahl (> 100)"""
with pytest.raises(ValueError, match="Score must be between 0 and 100"):
calculate_grade(150)
Hinweis zur Testorganisation:
- Jede Testmethode deckt eine Äquivalenzklasse ab (eine Testfunktion pro Ausgabekategorie)
- Innerhalb jedes Tests fügen wir mehrere Assertions ein - typischerweise:
- Ein repräsentativer Wert aus der Mitte des Bereichs (z.B. 95 für Note A)
- Grenzwerte an den Rändern des Bereichs (z.B. 90 und 100 für Note A)
- Dies kombiniert Äquivalenzklassentests (ein Test pro Klasse) mit Grenzwerttests (Testen der Ränder)
Beobachtung: Obwohl wir 6 Äquivalenzklassen haben, schrieben wir 7 Testfunktionen, weil die “ungültig”-Klasse tatsächlich zwei Untermuster hat: negative Punktzahlen und Punktzahlen > 100. Dies deutet darauf hin, dass Äquivalenzklassen manchmal unterteilt werden können, wenn es verschiedene Fehlerpfade gibt!
Für die Neugierigen: Mathematische Formalisierung von calculate_grade
Lassen Sie uns die Noten-Funktion mit dem diskreten Funktionsrahmen formalisieren:
-
Definiere die Funktion: \(g: \mathbb{Z} \rightarrow \{\text{"A"}, \text{"B"}, \text{"C"}, \text{"D"}, \text{"F"}, \text{Fehler}\}\)
Definitionsbereich: \(D = \mathbb{Z}\) (Ganzzahlen, praktisch interessieren uns \([-\infty, 0) \cup [0, 100] \cup (100, \infty]\))
- Ausgabekategorien (durch Code gegeben):
- \(C_1 = {\text{“A”}}\)
- \(C_2 = {\text{“B”}}\)
- \(C_3 = {\text{“C”}}\)
- \(C_4 = {\text{“D”}}\)
- \(C_5 = {\text{“F”}}\)
- \(C_6 = {\text{Fehler}}\) (ValueError-Ausnahme)
-
Äquivalenzrelation: Zwei Punktzahlen \(s_1 \sim s_2\) wenn \(g(s_1) = g(s_2)\) (gleiche Buchstabennote)
- Die induzierten Eingabe-Äquivalenzklassen:
- \(E_1 = {s \in \mathbb{Z} : g(s) \in C_1} = [90, 100]\) (Punktzahlen, die “A” erzeugen)
- \(E_2 = {s \in \mathbb{Z} : g(s) \in C_2} = [80, 90)\) (Punktzahlen, die “B” erzeugen)
- \(E_3 = {s \in \mathbb{Z} : g(s) \in C_3} = [70, 80)\) (Punktzahlen, die “C” erzeugen)
- \(E_4 = {s \in \mathbb{Z} : g(s) \in C_4} = [60, 70)\) (Punktzahlen, die “D” erzeugen)
- \(E_5 = {s \in \mathbb{Z} : g(s) \in C_5} = [0, 60)\) (Punktzahlen, die “F” erzeugen)
- \(E_6 = {s \in \mathbb{Z} : g(s) \in C_6} = (-\infty, 0) \cup (100, \infty)\) (ungültige Punktzahlen)
- Verifiziere die Partition:
- \(E_1 \cup E_2 \cup E_3 \cup E_4 \cup E_5 \cup E_6 = \mathbb{Z}\) ✅ (deckt alle Ganzzahlen ab)
- \(E_i \cap E_j = \emptyset\) für \(i \neq j\) ✅ (keine Überlappung - jede Punktzahl erzeugt genau eine Ausgabe)
- Wichtige mathematische Beobachtung:
- Anzahl der Klassen = 6 (genau die Anzahl der Ausgabekategorien - keine Wahl!)
- Jede Eingabeklasse \(E_i\) ist ein kontinuierliches Intervall (außer \(E_6\), das zwei disjunkte Intervalle ist)
- Grenzen sind wohldefiniert: 0, 60, 70, 80, 90, 100
Kontrast mit kontinuierlichen Funktionen:
Für reciprocal(x) wählten wir, ℝ in {positiv, negativ} zu partitionieren (hätte auch {< -1, [-1,0), (0,1], > 1} sein können).
Für calculate_grade(score) ist die Partition durch den Code bestimmt - die Schwellwerte (60, 70, 80, 90) und Ausgabewerte (“A”-“F”) sind fest codiert!
Deshalb sind diskrete Funktionen einfacher - die mathematische Struktur zeigt sich direkt aus dem Code, keine Designentscheidungen nötig!
Beispiel 2: Tupel/zusammengesetzte Rückgaben - validate_password(password)
Funktionsdefinition:
def validate_password(password: str) -> tuple[bool, str]:
"""
Validiere Passwortstärke.
Regeln:
- Länge: 8-20 Zeichen
- Muss mindestens einen Großbuchstaben enthalten
- Muss mindestens einen Kleinbuchstaben enthalten
- Muss mindestens eine Ziffer enthalten
- Muss mindestens ein Sonderzeichen (!@#$%^&*) enthalten
Args:
password: Zu validierender String
Returns:
tuple: (bool, str) - (ist_gültig, Fehlermeldung)
"""
if not isinstance(password, str):
return (False, "Password must be a string")
if len(password) < 8:
return (False, "Password too short (minimum 8 characters)")
if len(password) > 20:
return (False, "Password too long (maximum 20 characters)")
if not any(c.isupper() for c in password):
return (False, "Password must contain at least one uppercase letter")
if not any(c.islower() for c in password):
return (False, "Password must contain at least one lowercase letter")
if not any(c.isdigit() for c in password):
return (False, "Password must contain at least one digit")
special_chars = "!@#$%^&*"
if not any(c in special_chars for c in password):
return (False, "Password must contain at least one special character (!@#$%^&*)")
return (True, "Password is valid")
Frage: Was sind die Äquivalenzklassen für password?
Intuitiver Ansatz (White-Box-Testing):
Diese Funktion ist komplexer - sie gibt ein Tupel (bool, str) mit verschiedenen Fehlermeldungen zurück! Analysieren wir:
Beim Betrachten des Codes bemerken wir sofort:
- Zusammengesetzter Ausgabetyp - Die Funktion gibt
tuple[bool, str]zurück, aber praktisch:- Erstes Element ist immer
TrueoderFalse - Zweites Element ist einer von 8 möglichen Strings
- Erstes Element ist immer
- Mehrere Validierungsprüfungen - Der Code hat 8 verschiedene Validierungspfade:
- Typprüfung:
not isinstance(password, str) - Längenprüfungen:
len(password) < 8,len(password) > 20 - Zeichenanforderungen: Großbuchstaben, Kleinbuchstaben, Ziffer, Sonderzeichen
- Erfolgsfall: alle Prüfungen bestanden
- Typprüfung:
- Early-Return-Muster - Die Prüfungen sind sequenziell mit frühen Rückgaben:
- Erste fehlschlagende Prüfung bestimmt die Fehlermeldung
- Reihenfolge ist wichtig!
if len(password) < 8kommt vor der Großbuchstabenprüfung
- Endliche Ausgabemenge - Obwohl es ein Tupel ist, gibt es genau 8 mögliche Ausgaben:
(False, "Password must be a string")(False, "Password too short (minimum 8 characters)")(False, "Password too long (maximum 20 characters)")(False, "Password must contain at least one uppercase letter")(False, "Password must contain at least one lowercase letter")(False, "Password must contain at least one digit")(False, "Password must contain at least one special character (!@#$%^&*)")(True, "Password is valid")
Also identifizieren wir natürlich 8 Äquivalenzklassen:
| Äquivalenzklasse | Beschreibung | Repräsentativer Wert | Erwartete Ausgabe |
|---|---|---|---|
| Gültiges Passwort | Erfüllt alle Anforderungen (8-20 Zeichen, Groß-, Kleinbuchstaben, Ziffer, Sonderzeichen) | "SecurePwd1!" |
(True, "Password is valid") |
| Kein String | Eingabe ist kein String-Typ | 12345 oder None |
(False, "Password must be a string") |
| Zu kurz | Länge < 8 Zeichen | "Abc1!" |
(False, "Password too short ...") |
| Zu lang | Länge > 20 Zeichen | "VeryLongPassword123!Extra" |
(False, "Password too long ...") |
| Fehlender Großbuchstabe | Keine Großbuchstaben (aber besteht Längenprüfungen) | "password1!" |
(False, "... uppercase letter") |
| Fehlender Kleinbuchstabe | Keine Kleinbuchstaben (aber besteht vorherige Prüfungen) | "PASSWORD1!" |
(False, "... lowercase letter") |
| Fehlende Ziffer | Keine Ziffern (aber besteht vorherige Prüfungen) | "Password!" |
(False, "... digit") |
| Fehlendes Sonderzeichen | Keine Sonderzeichen (aber besteht vorherige Prüfungen) | "Password1" |
(False, "... special character ...") |
Warum diese acht Klassen?
-
Jede
if-Anweisung erzeugt eine potenzielle Äquivalenzklasse - Die sequenziellen Prüfungen partitionieren den Eingaberaum in 8 Kategorien -
Reihenfolge ist wichtig! - Wegen früher Rückgaben wird ein Passwort, das sowohl zu kurz ist ALS AUCH Großbuchstaben fehlen, als “zu kurz” klassifiziert (erste fehlschlagende Prüfung gewinnt)
-
Zusammengesetzte Ausgabe ist immer noch diskret - Obwohl der Rückgabetyp
tuple[bool, str]ist, gibt es nur 8 mögliche Tupel -
Testen erfordert Repräsentanten von jedem Validierungspfad - Wir müssen jede spezifische Fehlermeldung auslösen
Kernerkenntnis: Funktionen mit mehreren Validierungsprüfungen erzeugen natürlich mehrere Äquivalenzklassen - eine für Erfolg, eine für jeden Fehlermodus!
Test-Code:
import pytest
def test_validate_password_valid():
"""Äquivalenzklasse: Gültiges Passwort (alle Anforderungen erfüllt)"""
assert validate_password("SecurePwd1!") == (True, "Password is valid")
assert validate_password("MyP@ssw0rd") == (True, "Password is valid")
def test_validate_password_not_string():
"""Äquivalenzklasse: Eingabe ist kein String"""
assert validate_password(12345) == (False, "Password must be a string")
assert validate_password(None) == (False, "Password must be a string")
def test_validate_password_too_short():
"""Äquivalenzklasse: Passwort zu kurz (< 8 Zeichen)"""
result = validate_password("Abc1!")
assert result[0] == False
assert "too short" in result[1]
def test_validate_password_too_long():
"""Äquivalenzklasse: Passwort zu lang (> 20 Zeichen)"""
result = validate_password("VeryLongPassword123!Extra")
assert result[0] == False
assert "too long" in result[1]
def test_validate_password_missing_uppercase():
"""Äquivalenzklasse: Kein Großbuchstabe"""
result = validate_password("password1!")
assert result[0] == False
assert "uppercase" in result[1]
def test_validate_password_missing_lowercase():
"""Äquivalenzklasse: Kein Kleinbuchstabe"""
result = validate_password("PASSWORD1!")
assert result[0] == False
assert "lowercase" in result[1]
def test_validate_password_missing_digit():
"""Äquivalenzklasse: Keine Ziffer"""
result = validate_password("Password!")
assert result[0] == False
assert "digit" in result[1]
def test_validate_password_missing_special():
"""Äquivalenzklasse: Kein Sonderzeichen"""
result = validate_password("Password1")
assert result[0] == False
assert "special character" in result[1]
Testdesign-Beobachtungen:
- Ein Test pro Äquivalenzklasse - 8 Tests für 8 Klassen
- Tupel-Entpacken - Wir können
result[0](Boolean) undresult[1](Nachricht) separat prüfen - Partielle String-Übereinstimmung - Verwendung von
"uppercase" in result[1]macht Tests widerstandsfähiger gegen Änderungen in der Nachrichtenformulierung - Repräsentative Werte sorgfältig gewählt - Jeder Testfall löst genau einen spezifischen Validierungsfehler aus
Fortgeschrittene Überlegung: Was ist mit Passwörtern, die mehrere Prüfungen nicht bestehen?
Beispiel: "abc" (zu kurz, fehlen Großbuchstaben, Ziffer, Sonderzeichen)
Frage: Zu welcher Äquivalenzklasse gehört es?
Antwort: Zur “zu kurz”-Klasse, weil das die erste Prüfung ist, die fehlschlägt (Early-Return-Muster)!
Dies zeigt, dass Äquivalenzklassen konzeptionell überlappen können, aber der Ausführungspfad der Funktion bestimmt die tatsächliche Klasse. Deshalb ist White-Box-Testing (Code sehen) so wertvoll!
Für die Neugierigen: Mathematische Formalisierung von validate_password
Diese Funktion demonstriert, wie zusammengesetzte Rückgabetypen immer noch diskrete Äquivalenzklassen erzeugen:
-
Definiere die Funktion: \(h: \Sigma^* \rightarrow \{o_1, o_2, \ldots, o_8\}\)
Definitionsbereich: \(\Sigma^* = \) alle möglichen Strings (einschließlich Nicht-Strings für Typprüfung)
Ausgabemenge (8 mögliche Tupel):
- \(o_1 = (\text{True}, \text{“Password is valid”})\)
- \(o_2 = (\text{False}, \text{“Password must be a string”})\)
- \(o_3 = (\text{False}, \text{“Password too short…”})\)
- … (und 5 weitere spezifische Fehler-Tupel)
- Ausgabekategorien (durch Code-Pfade gegeben):
- \(C_i = \{o_i\}\) für \(i = 1, 2, \ldots, 8\) (jede mögliche Ausgabe ist ihre eigene Kategorie)
-
Äquivalenzrelation: \(p_1 \sim p_2 \iff h(p_1) = h(p_2)\)
Zwei Passwörter sind äquivalent, wenn sie das gleiche Tupel erzeugen (gleicher Boolean + gleiche Fehlermeldung)
- Die induzierten Eingabe-Äquivalenzklassen:
- \(E_1 = \{p : h(p) = o_1\}\) (gültige Passwörter)
- \(E_2 = \{p : h(p) = o_2\}\) (Nicht-String-Eingaben)
- \(E_3 = \{p : h(p) = o_3\}\) (zu kurz)
- … (und 5 weitere Klassen für andere Validierungsfehler)
-
Wichtige mathematische Beobachtung:
Sequenzielle Validierung erzeugt eine Hierarchie:
Bezeichnen wir die Validierungsprädikate:
- \(P_1(p)\):
isinstance(p, str) - \(P_2(p)\):
len(p) >= 8 - \(P_3(p)\):
len(p) <= 20 - \(P_4(p)\):
has_uppercase(p) - \(P_5(p)\):
has_lowercase(p) - \(P_6(p)\):
has_digit(p) - \(P_7(p)\):
has_special(p)
Die Äquivalenzklassen sind:
- \(E_1 = \{p : P_1(p) \land P_2(p) \land P_3(p) \land P_4(p) \land P_5(p) \land P_6(p) \land P_7(p)\}\) (alle bestehen)
- \(E_2 = \{p : \neg P_1(p)\}\) (erste Prüfung schlägt fehl)
- \(E_3 = \{p : P_1(p) \land \neg P_2(p)\}\) (zweite Prüfung schlägt fehl, erste besteht)
- \(E_4 = \{p : P_1(p) \land P_2(p) \land \neg P_3(p)\}\) (dritte Prüfung schlägt fehl, vorherige bestehen)
- … und so weiter
Dies ist eine hierarchische Partition - jede Klasse ist definiert durch:
- Alle vorherigen Prüfungen bestehen (wegen früher Rückgaben)
- Aktuelle Prüfung schlägt fehl (oder alle bestehen für gültigen Fall)
- \(P_1(p)\):
- Verifiziere die Partition:
- Disjunkt: ✅ Jede Eingabe löst genau eine Return-Anweisung aus (erste übereinstimmende Prüfung)
- Vollständig: ✅ Jede mögliche Eingabe wird irgendeinen Return-Pfad ausführen
Kernerkenntnis: Selbst mit zusammengesetzten/Tupel-Rückgabetypen hat die Funktion immer noch endlich viele mögliche Ausgaben (8 Tupel), was 8 Äquivalenzklassen erzeugt!
Kontrast mit Beispiel 1 (calculate_grade):
- Notenfunktion: Unabhängige Bereiche (Punktzahl 89 und 90 sind in verschiedenen Klassen, Punkt)
- Passwortfunktion: Hierarchische Prüfungen (Passwörter können mehrere Regeln verletzen, werden aber nach erstem Fehler klassifiziert)
Beide sind diskret, aber die Struktur der Eingabeklassen unterscheidet sich basierend auf der Validierungslogik!
Beispiel 3: Hybrid Diskret - calculate_shipping_cost(weight, distance, express)
Funktionsdefinition:
def calculate_shipping_cost(weight: float, distance: float, express: bool = False) -> float:
"""
Berechne Versandkosten basierend auf Gewicht und Entfernung.
Args:
weight: Gewicht in kg (0.1 bis 50)
distance: Entfernung in km (1 bis 5000)
express: Ob Expressversand gewünscht wird
Returns:
float: Versandkosten in EUR
Raises:
ValueError: Wenn Gewicht oder Entfernung außerhalb des gültigen Bereichs liegt
"""
if weight < 0.1 or weight > 50:
raise ValueError("Weight must be between 0.1 and 50 kg")
if distance < 1 or distance > 5000:
raise ValueError("Distance must be between 1 and 5000 km")
# Basiskostenberechnung
if weight <= 5:
base_cost = 5.0
elif weight <= 20:
base_cost = 10.0
else:
base_cost = 20.0
# Entfernungsmultiplikator
if distance <= 100:
distance_multiplier = 1.0
elif distance <= 500:
distance_multiplier = 1.5
else:
distance_multiplier = 2.0
cost = base_cost * distance_multiplier
# Expressversand addiert 50%
if express:
cost *= 1.5
return round(cost, 2)
Frage: Was sind die Äquivalenzklassen für diese Funktion?
Intuitiver Ansatz (White-Box-Testing):
Dies ist eine hybride Funktion - kontinuierliche Eingaben (Gewicht, Entfernung) aber diskrete Kostenkategorien! Analysieren wir:
Beim Betrachten des Codes bemerken wir sofort:
- Kontinuierliche Eingaben, diskrete Ausgaben - Eingaben sind Floats (Gewicht, Entfernung), aber die Logik gruppiert sie in diskrete Kategorien:
- Gewichtsbereiche: ≤5 kg, 5-20 kg, >20 kg
- Entfernungsbereiche: ≤100 km, 100-500 km, >500 km
- Express: Boolean (True/False)
-
Multiplikative Struktur - Kosten = base_cost × distance_multiplier × (1.5 wenn express sonst 1.0)
- Endliche Ausgabemenge - Obwohl Rückgabetyp
floatist, gibt es nur 18 mögliche Nicht-Fehler-Kosten:- 3 Basiskosten × 3 Entfernungsmultiplikatoren × 2 Express-Optionen = 18 Kombinationen
- Plus 2 Fehlerkategorien (ungültiges Gewicht, ungültige Entfernung)
- Mehrdimensionaler Eingaberaum - Drei Parameter erzeugen einen 3D-Eingaberaum, der aber in diskrete Zellen partitioniert ist
Also identifizieren wir Äquivalenzklassen über mehrere Dimensionen:
Dimension 1: Gewichtskategorien (3 Klassen)
| Gewichtsklasse | Bereich | Basiskosten | Repräsentant |
|---|---|---|---|
| Leicht | 0.1 ≤ weight ≤ 5 |
€5.00 | 2.5 kg |
| Mittel | 5 < weight ≤ 20 |
€10.00 | 10 kg |
| Schwer | 20 < weight ≤ 50 |
€20.00 | 30 kg |
Dimension 2: Entfernungskategorien (3 Klassen)
| Entfernungsklasse | Bereich | Multiplikator | Repräsentant |
|---|---|---|---|
| Lokal | 1 ≤ distance ≤ 100 |
1.0× | 50 km |
| Regional | 100 < distance ≤ 500 |
1.5× | 250 km |
| Fernstrecke | 500 < distance ≤ 5000 |
2.0× | 1000 km |
Dimension 3: Expressversand (2 Klassen)
| Express-Klasse | Wert | Multiplikator |
|---|---|---|
| Standard | False |
1.0× |
| Express | True |
1.5× |
Dimensionen kombinieren:
Gesamt gültige Kombinationen: 3 (Gewicht) × 3 (Entfernung) × 2 (Express) = 18 Kostenklassen
Plus 2 Fehlerklassen:
- Ungültiges Gewicht (< 0.1 oder > 50 kg)
- Ungültige Entfernung (< 1 oder > 5000 km)
Gesamt: 20 Äquivalenzklassen
Kernerkenntnis: Obwohl Gewicht und Entfernung kontinuierliche Eingaben sind (unendlich viele mögliche Werte), partitioniert die bedingte Logik der Funktion sie in diskrete Eimer, was zu einer endlichen Menge von Verhalten führt!
Dies ist grundlegend anders als reciprocal(x), wo:
reciprocal(x): Kontinuierliche Eingabe → Kontinuierliche Ausgabe (wir wählten wie zu partitionieren)calculate_shipping_cost(...): Kontinuierliche Eingaben → Diskrete Kostenkategorien (Partition durch Code bestimmt)
Test-Code:
import pytest
# Gewichtsdimensions-Tests
def test_shipping_cost_light_local_standard():
"""Äquivalenzklasse: Leicht (≤5kg) + Lokal (≤100km) + Standard"""
cost = calculate_shipping_cost(weight=2.5, distance=50, express=False)
assert cost == 5.0 # base=5.0, dist_mult=1.0, express=1.0 → 5.0
def test_shipping_cost_medium_local_standard():
"""Äquivalenzklasse: Mittel (5-20kg) + Lokal (≤100km) + Standard"""
cost = calculate_shipping_cost(weight=10, distance=50, express=False)
assert cost == 10.0 # base=10.0, dist_mult=1.0, express=1.0 → 10.0
def test_shipping_cost_heavy_local_standard():
"""Äquivalenzklasse: Schwer (>20kg) + Lokal (≤100km) + Standard"""
cost = calculate_shipping_cost(weight=30, distance=50, express=False)
assert cost == 20.0 # base=20.0, dist_mult=1.0, express=1.0 → 20.0
# Entfernungsdimensions-Tests
def test_shipping_cost_light_regional_standard():
"""Äquivalenzklasse: Leicht (≤5kg) + Regional (100-500km) + Standard"""
cost = calculate_shipping_cost(weight=2.5, distance=250, express=False)
assert cost == 7.5 # base=5.0, dist_mult=1.5, express=1.0 → 7.5
def test_shipping_cost_light_longdist_standard():
"""Äquivalenzklasse: Leicht (≤5kg) + Fernstrecke (>500km) + Standard"""
cost = calculate_shipping_cost(weight=2.5, distance=1000, express=False)
assert cost == 10.0 # base=5.0, dist_mult=2.0, express=1.0 → 10.0
# Express-Dimensions-Tests
def test_shipping_cost_light_local_express():
"""Äquivalenzklasse: Leicht (≤5kg) + Lokal (≤100km) + Express"""
cost = calculate_shipping_cost(weight=2.5, distance=50, express=True)
assert cost == 7.5 # base=5.0, dist_mult=1.0, express=1.5 → 7.5
def test_shipping_cost_medium_regional_express():
"""Äquivalenzklasse: Mittel (5-20kg) + Regional (100-500km) + Express"""
cost = calculate_shipping_cost(weight=10, distance=250, express=True)
assert cost == 22.5 # base=10.0, dist_mult=1.5, express=1.5 → 22.5
def test_shipping_cost_heavy_longdist_express():
"""Äquivalenzklasse: Schwer (>20kg) + Fernstrecke (>500km) + Express"""
cost = calculate_shipping_cost(weight=30, distance=1000, express=True)
assert cost == 60.0 # base=20.0, dist_mult=2.0, express=1.5 → 60.0
# Grenzwerttests (testen auch Äquivalenzklassengrenzen)
def test_shipping_cost_weight_boundary_5kg():
"""Grenze: weight = 5.0 (Rand der Leicht/Mittel-Klassen)"""
assert calculate_shipping_cost(5.0, 50) == 5.0 # Leicht-Klasse
assert calculate_shipping_cost(5.1, 50) == 10.0 # Mittel-Klasse
def test_shipping_cost_weight_boundary_20kg():
"""Grenze: weight = 20.0 (Rand der Mittel/Schwer-Klassen)"""
assert calculate_shipping_cost(20.0, 50) == 10.0 # Mittel-Klasse
assert calculate_shipping_cost(20.1, 50) == 20.0 # Schwer-Klasse
def test_shipping_cost_distance_boundary_100km():
"""Grenze: distance = 100 (Rand der Lokal/Regional-Klassen)"""
assert calculate_shipping_cost(2.5, 100) == 5.0 # Lokal-Klasse
assert calculate_shipping_cost(2.5, 101) == 7.5 # Regional-Klasse
def test_shipping_cost_distance_boundary_500km():
"""Grenze: distance = 500 (Rand der Regional/Fernstrecken-Klassen)"""
assert calculate_shipping_cost(2.5, 500) == 7.5 # Regional-Klasse
assert calculate_shipping_cost(2.5, 501) == 10.0 # Fernstrecken-Klasse
# Fehler-Tests
def test_shipping_cost_invalid_weight_too_low():
"""Äquivalenzklasse: Ungültiges Gewicht (< 0.1 kg)"""
with pytest.raises(ValueError, match="Weight must be between 0.1 and 50 kg"):
calculate_shipping_cost(0.05, 100)
def test_shipping_cost_invalid_weight_too_high():
"""Äquivalenzklasse: Ungültiges Gewicht (> 50 kg)"""
with pytest.raises(ValueError, match="Weight must be between 0.1 and 50 kg"):
calculate_shipping_cost(100, 100)
def test_shipping_cost_invalid_distance_too_low():
"""Äquivalenzklasse: Ungültige Entfernung (< 1 km)"""
with pytest.raises(ValueError, match="Distance must be between 1 and 5000 km"):
calculate_shipping_cost(10, 0.5)
def test_shipping_cost_invalid_distance_too_high():
"""Äquivalenzklasse: Ungültige Entfernung (> 5000 km)"""
with pytest.raises(ValueError, match="Distance must be between 1 and 5000 km"):
calculate_shipping_cost(10, 6000)
Testdesign-Beobachtungen:
- Kombinatorische Abdeckung - Wir testen nicht alle 18 gültigen Kombinationen (das wäre redundant). Stattdessen:
- Testen jede Dimension unabhängig (Leicht/Mittel/Schwer-Gewichte)
- Testen Kombinationen von Dimensionen (Leicht+Regional, Mittel+Express, etc.)
- Decken mindestens einen Repräsentanten aus jeder Klasse ab
-
Grenzwerte sind entscheidend - Die Tests prüfen explizit Werte wie
weight=5.0vsweight=5.1, um zu verifizieren, dass die Partitionsgrenzen korrekt sind - Dies demonstriert den Unterschied zwischen Äquivalenzklassentests und erschöpfendem Testen:
- Erschöpfend: 18 Tests für alle gültigen Kombinationen
- Äquivalenzklasse: 8-12 Tests, die Schlüsselrepräsentanten und Grenzen abdecken
- Wir erreichen gute Abdeckung ohne erschöpfendes Testen!
Praktische Teststrategie:
Für Funktionen mit mehrdimensionalen diskreten Ausgaben, verwende:
- Ein Test pro Dimension (3 Gewichtstests, 3 Entfernungstests, 2 Express-Tests)
- Grenztests für Übergangspunkte (Gewicht=5, 20; Entfernung=100, 500)
- Ein paar Kombinationstests, um zu verifizieren, dass die Multiplikationslogik funktioniert
- Fehler-Tests für ungültige Eingaben
Dies ergibt ~15 Tests statt 18+ erschöpfender Tests!
Für die Neugierigen: Mathematische Formalisierung hybrider diskreter Funktionen
Diese Funktion demonstriert kontinuierliche Eingaben, die auf diskrete Ausgaben abbilden:
-
Definiere die Funktion: \(k: [0.1, 50] \times [1, 5000] \times \{0, 1\} \rightarrow \mathbb{R}\)
Definitionsbereich:
- \(W = [0.1, 50]\) (gültige Gewichte in kg)
- \(D = [1, 5000]\) (gültige Entfernungen in km)
- \(E = \{0, 1\}\) (Express: False=0, True=1)
Ausgabe: Reelle Zahlen (Kosten in EUR)
-
Partitioniere die Eingabebereiche:
Gewichtspartitionen:
- \(W_1 = [0.1, 5]\) (leicht)
- \(W_2 = (5, 20]\) (mittel)
- \(W_3 = (20, 50]\) (schwer)
Entfernungspartitionen:
- \(D_1 = [1, 100]\) (lokal)
- \(D_2 = (100, 500]\) (regional)
- \(D_3 = (500, 5000]\) (Fernstrecke)
Express-Partitionen:
- \(E_1 = \{0\}\) (Standard)
- \(E_2 = \{1\}\) (Express)
-
Ausgabekategorien (diskret, durch Eingabepartitionen bestimmt):
Jede Kombination von (Gewichtsklasse, Entfernungsklasse, Express-Klasse) erzeugt eindeutige Kosten:
\[C_{ijk} = \text{basis}(W_i) \times \text{mult}(D_j) \times \text{express}(E_k)\]Wobei:
- \(\text{basis}(W_1) = 5.0, \text{basis}(W_2) = 10.0, \text{basis}(W_3) = 20.0\)
- \(\text{mult}(D_1) = 1.0, \text{mult}(D_2) = 1.5, \text{mult}(D_3) = 2.0\)
- \(\text{express}(E_1) = 1.0, \text{express}(E_2) = 1.5\)
Gesamt Ausgabekategorien: 3 × 3 × 2 = 18 eindeutige Kosten
-
Äquivalenzrelation:
Zwei Eingaben \((w_1, d_1, e_1) \sim (w_2, d_2, e_2)\) wenn:
- \(w_1\) und \(w_2\) sind in derselben Gewichtspartition \(W_i\), UND
- \(d_1\) und \(d_2\) sind in derselben Entfernungspartition \(D_j\), UND
- \(e_1 = e_2\) (gleicher Express-Wert)
Dies erzeugt eine Produktpartition des Eingaberaums.
-
Die induzierten Eingabe-Äquivalenzklassen:
\[E_{ijk} = W_i \times D_j \times E_k\]Zum Beispiel:
- \(E_{111} = [0.1, 5] \times [1, 100] \times \{0\}\) (leicht, lokal, Standard) → Kosten = €5.00
- \(E_{232} = (5, 20] \times (100, 500] \times \{1\}\) (mittel, regional, Express) → Kosten = €22.50
-
Verifiziere die Partition:
- Disjunkt: ✅ Jedes Eingabetupel fällt in genau ein \(E_{ijk}\)
- Vollständig: ✅ Alle gültigen Eingaben abgedeckt durch Vereinigung aller \(E_{ijk}\)
Wichtige mathematische Erkenntnis:
Kontrast mit rein diskreten Funktionen:
- Notenfunktion: Eingabebereich ist bereits diskret (Ganzzahlen 0-100)
- Versandfunktion: Eingabebereich ist kontinuierlich (reelle Intervalle), aber partitioniert in diskrete Zellen
Dies ist in realen Systemen üblich - kontinuierliche Messungen (Gewicht, Entfernung, Temperatur, etc.) werden in diskrete Kategorien eingeordnet für Entscheidungsfindung!
Implikationen für Tests:
- Grenzwerte sind kritisch - Müssen Partitionsränder testen (5.0 vs 5.1 kg)
- Repräsentative Stichprobe - Wähle einen Wert aus dem Inneren jeder Partitionszelle
- Keine erschöpfende Abdeckung nötig - Ein Test pro Zelle ist ausreichend (18 Tests max)
Dieses hybride Muster erscheint häufig:
- Steuerklassen (kontinuierliches Einkommen → diskrete Steuersätze)
- Versicherungsprämien (kontinuierliches Alter → diskrete Risikokategorie)
- Qualitätsnoten (kontinuierliche Messungen → diskrete Bewertungen)
Die Mathematik ist dieselbe wie bei rein diskreten Funktionen, außer dass die Eingabeklassen kontinuierliche Regionen statt diskreter Mengen sind!
Kernerkenntnisse: Diskrete vs. Kontinuierliche Äquivalenzklassen
Lassen Sie uns zurücktreten und vergleichen, was wir über diskrete und kontinuierliche Funktionen gelernt haben:
| Aspekt | Kontinuierliche Funktionen | Diskrete Funktionen |
|---|---|---|
| Ausgaberaum | Unendlich (ℝ oder ℝ ∪ {None}) | Endliche Menge (Strings, Enums, Tupel) |
| Ausgabepartitionierung | Sie wählen wie zu partitionieren (Designentscheidung) | Vordefiniert durch Rückgabetyp/Logik der Funktion |
| Anzahl der Klassen | Abhängig von Ihrer Granularitätswahl (3? 4? 5?) | Gleich Anzahl möglicher Ausgaben (fest) |
| Hauptherausforderung | "Wie soll ich unendliche Ausgaben partitionieren?" | "Welche Eingaben erzeugen welche Ausgabe?" |
| Beispiele aus der Vorlesung | reciprocal(x), reciprocal_sum(x,y,z), calculate_ray_slope(angle) |
calculate_grade(score), validate_password(pwd), calculate_shipping_cost(...) |
| Testdesign-Fokus | Vorzeichengrenzen, Null, Spezialwerte | Kategoriegrenzen, alle Validierungspfade |
Wann sind diskrete Funktionen einfacher zu testen?
- Ausgabekategorien sind offensichtlich - Liste einfach alle möglichen Rückgabewerte auf!
- Keine Granularitätsdebatten - Die Funktionssignatur sagt Ihnen die Klassen
- Vollständige Abdeckung ist erreichbar - 6 Noten? Schreibe 6 Tests!
Wann sind diskrete Funktionen schwieriger zu testen?
- Viele mögliche Ausgaben - 8 Validierungsfehler = 8 Testfälle minimum
- Kombinatorische Explosion - 3 × 3 × 2 = 18 Klassen für Versandkosten
- Hierarchische Validierung - Reihenfolge ist wichtig (Passwortvalidierung)
- Grenzwerte immer noch kritisch - Notengrenzen (89 vs 90) können Bugs verbergen
Die Erkenntnis: Diskrete Funktionen vereinfachen Ausgabepartitionierung, beseitigen aber nicht die Notwendigkeit sorgfältiger Eingabeanalyse!
Verbindung zu find_intersection(): Diskrete Ausgabekategorien erkennen
Erinnern Sie sich an die komplexe find_intersection()-Funktion, die wir später analysieren werden? Sie hat diskrete Ausgabekategorien, die sich auf den ersten Blick verbergen!
def find_intersection(
road_profile: list[tuple[float, float]],
camera_angle: float,
camera_position: tuple[float, float]
) -> tuple[float, float] | None:
"""Finde wo Kamerastrahl Straßenprofil schneidet."""
# ... komplexer Geometrie-Code ...
Auf den ersten Blick sieht dies wie eine kontinuierliche Funktion aus:
- Eingabe: Floats (Winkel, Positionskoordinaten, Straßenpunkte)
- Ausgabe:
tuple[float, float] | None(Schnittpunktkoordinaten oder None)
Aber warte! Die ergebnisbasierten Äquivalenzklassen sind diskret:
- Kein Schnittpunkt → Gibt
Nonezurück (Strahl verfehlt Straße) - Schnittpunkt gefunden → Gibt
tuple[float, float]zurück (Koordinaten)
Und innerhalb von “Schnittpunkt gefunden” gibt es diskrete geometrische Fälle:
- Strahl schneidet aufsteigendes Segment
- Strahl schneidet absteigendes Segment
- Strahl schneidet horizontales Segment
- Strahl schneidet an Vertex (Grenzfall)
Dies ist eine hybride Funktion - genau wie calculate_shipping_cost!
- Kontinuierliche Eingaben (Winkel, Koordinaten) → Diskrete geometrische Ergebnisse
Die Lektion: Selbst wenn eine Funktion kontinuierliche Werte zurückgibt (wie Koordinaten), können Sie oft diskrete Verhaltenskategorien identifizieren, die separat getestet werden sollten!
Teststrategie für find_intersection():
- Teste keine zufälligen Winkel/Positions-Kombinationen (das ist unendlich!)
- Identifiziere die diskreten Ergebniskategorien (Schnittpunkttypen, None-Fälle)
- Wähle repräsentative Eingaben, die jede Kategorie auslösen
- Teste Grenzfälle (vertikale Strahlen, horizontale Segmente, Vertices)
Das ist genau das, was wir mit calculate_shipping_cost gemacht haben:
- Teste keine zufälligen Gewichte/Entfernungen
- Partitioniere in diskrete Zellen (leicht/mittel/schwer × lokal/regional/fern)
- Teste Repräsentanten + Grenzen
Die Kraft des Denkens in Äquivalenzklassen: Es transformiert unlösbares kontinuierliches Testen in handhabbares diskretes Testen!
Praktische Richtlinien: Wann diskrete vs. kontinuierliche Analyse verwenden
Verwende diskrete Äquivalenzklassen-Analyse wenn:
- ✅ Funktion gibt endliche Menge von Werten zurück (Strings, Enums, feste Ganzzahlen)
- ✅ Funktion hat explizite Validierung mit spezifischen Fehlermeldungen
- ✅ Funktion verwendet schwellwertbasierte Logik (if-else-Ketten)
- ✅ Funktion bildet kontinuierliche Eingaben auf diskrete Kategorien ab (Einordnung)
Beispiele: Notenrechner, Validatoren, Genehmigungsworkflows, Risikoklassifizierer
Verwende kontinuierliche Äquivalenzklassen-Analyse wenn:
- ✅ Funktion führt mathematische Berechnungen mit reellen Zahlen durch
- ✅ Ausgabe ist wirklich kontinuierlich (keine natürlichen Schwellwerte)
- ✅ Sie müssen Granularität basierend auf Domänensignifikanz wählen
Beispiele: Trigonometrische Funktionen, wissenschaftliche Berechnungen, Physiksimulationen
Verwende hybride Analyse (beides!) wenn:
- ✅ Funktion nimmt kontinuierliche Eingaben, erzeugt aber diskrete Ergebnisse
- ✅ Funktion hat geometrische oder physikalische Einschränkungen, die natürliche Grenzen schaffen
- ✅ Funktion kombiniert Berechnungen mit bedingter Logik
Beispiele: Schnittpunktfindung, Trajektorienberechnungen, Sensor-Schwellwertdetektoren
Das Urteil:
Die meisten realen Funktionen sind hybrid - sie beinhalten sowohl kontinuierliche Mathematik als auch diskrete Entscheidungslogik. Die Fähigkeit ist zu erkennen, welche Linse wo anzuwenden ist!
Für find_intersection() werden wir verwenden:
- Diskrete Analyse für Ergebniskategorien (Schnittpunkttypen)
- Kontinuierliche Analyse für Winkelbereiche (aufwärts/abwärts/horizontal/vertikal)
- Strukturelle Analyse für Straßenprofilformen (aufsteigend/absteigend/flache Segmente)
Dieser mehrdimensionale Ansatz ist es, was das Testen komplexer Funktionen handhabbar macht!
1.1.9 Array-Eingabe einfach: array_sum(arr)
Funktionsdefinition:
def array_sum(arr: NDArray[np.float64]) -> float:
"""Return the sum of array elements."""
if len(arr) == 0:
raise ValueError("Cannot sum empty array")
return float(np.sum(arr))
Frage: Was sind die Äquivalenzklassen für einen Array-Parameter?
Neue Dimension: Struktur
Arrays führen strukturelle Äquivalenzklassen zusätzlich zu Wert-Klassen ein:
| Strukturelle Klasse | Beschreibung | Repräsentant | Warum wichtig |
|---|---|---|---|
| Leeres Array | len(arr) = 0 |
np.array([]) |
Grenzfall - keine Elemente |
| Einzelnes Element | len(arr) = 1 |
np.array([5.0]) |
Minimales Nicht-Leer |
| Zwei Elemente | len(arr) = 2 |
np.array([3.0, 4.0]) |
Kleinster nicht-trivialer Fall |
| Viele Elemente | len(arr) > 10 |
np.array([1.0, 2.0, ..., 20.0]) |
Typischer Fall |
Wert-basierte Äquivalenzklassen:
| Wert-Klasse | Beschreibung | Repräsentant | Erwartetes Ergebnis |
|---|---|---|---|
| Alle positiv | Alle Elemente > 0 | [1.0, 2.0, 3.0] |
Positive Summe (6.0) |
| Alle negativ | Alle Elemente < 0 | [-1.0, -2.0, -3.0] |
Negative Summe (-6.0) |
| Gemischte Vorzeichen | Einige pos, einige neg | [5.0, -2.0, 3.0] |
Summe hängt von Werten ab (6.0) |
| Enthält Nullen | Mindestens eine Null | [0.0, 1.0, 2.0] |
Nullen beeinflussen Summe nicht (3.0) |
| Alle Nullen | Alle Elemente sind 0 | [0.0, 0.0, 0.0] |
Summe ist Null (0.0) |
Kombinierte Komplexität:
Arrays haben ZWEI Dimensionen von Äquivalenzklassen:
- Strukturell (Länge): leer, einzeln, zwei, viele
- Wert-basiert (Inhalt): positiv, negativ, gemischt, Nullen
Kombinationen: 4 strukturell × 5 Wert = 20 potenzielle Testfälle!
(In der Praxis ergeben nicht alle Kombinationen Sinn - z.B. “leeres Array mit allen positiven Werten” ist widersprüchlich.)
Test-Beispiele:
# STRUKTURELLE TESTS
def test_array_sum_empty_array():
"""Structural class: Empty array"""
with pytest.raises(ValueError):
array_sum(np.array([]))
def test_array_sum_single_element():
"""Structural class: Single element"""
result = array_sum(np.array([5.0]))
assert result == 5.0
def test_array_sum_two_elements():
"""Structural class: Two elements (minimum non-trivial)"""
result = array_sum(np.array([3.0, 4.0]))
assert result == 7.0
def test_array_sum_many_elements():
"""Structural class: Many elements"""
arr = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0])
result = array_sum(arr)
assert result == 55.0
# WERT-BASIERTE TESTS
def test_array_sum_all_positive():
"""Value class: All positive numbers"""
result = array_sum(np.array([1.0, 2.0, 3.0]))
assert result == 6.0
def test_array_sum_all_negative():
"""Value class: All negative numbers"""
result = array_sum(np.array([-1.0, -2.0, -3.0]))
assert result == -6.0
def test_array_sum_mixed_signs():
"""Value class: Mixed positive and negative"""
result = array_sum(np.array([5.0, -2.0, 3.0]))
assert result == 6.0
def test_array_sum_contains_zeros():
"""Value class: Contains zeros"""
result = array_sum(np.array([0.0, 1.0, 2.0]))
assert result == 3.0
def test_array_sum_all_zeros():
"""Value class: All elements are zero"""
result = array_sum(np.array([0.0, 0.0, 0.0]))
assert result == 0.0
Wichtige Einsicht: Arrays führen eine strukturelle Dimension zu Äquivalenzklassen ein. Sie müssen beides testen:
- Struktur (Länge, Form)
- Werte (Inhaltsmuster)
Deshalb sind Array-Funktionen schwieriger vollständig zu testen!
1.1.10 Komplexes Array-Beispiel: find_intersection()
Nun tackeln wir die echte Funktion aus Ihrem Road Profile Viewer-Projekt. Hier wird die Äquivalenzklassen-Analyse wirklich schwierig – selbst für KI-Assistenten.
Vollständiger Funktionscode:
from numpy.typing import NDArray
import numpy as np
def find_intersection(
x_road: NDArray[np.float64],
y_road: NDArray[np.float64],
angle_degrees: float,
camera_x: float = 0,
camera_y: float = 1.5,
) -> tuple[float | None, float | None, float | None]:
"""
Find the intersection point between the camera ray and the road profile.
Parameters:
-----------
x_road : np.array
X-coordinates of the road profile
y_road : np.array
Y-coordinates of the road profile
angle_degrees : float
Angle of the camera ray in degrees
camera_x : float
X-coordinate of camera position
camera_y : float
Y-coordinate of camera position
Returns:
--------
tuple of (float, float, float) or (None, None, None)
x, y coordinates of intersection and distance from camera,
or None if no intersection
"""
angle_rad = -np.deg2rad(angle_degrees)
# Handle vertical ray
if np.abs(np.cos(angle_rad)) < 1e-10:
return None, None, None
slope = np.tan(angle_rad)
# Ray equation: y = camera_y + slope * (x - camera_x)
# Check each segment of the road for intersection
for i in range(len(x_road) - 1):
x1, y1 = x_road[i], y_road[i]
x2, y2 = x_road[i + 1], y_road[i + 1]
# Skip if this segment is behind the camera
if x2 <= camera_x:
continue
# Calculate y values of the ray at x1 and x2
ray_y1 = camera_y + slope * (x1 - camera_x)
ray_y2 = camera_y + slope * (x2 - camera_x)
# Check if the ray crosses the road segment
diff1 = ray_y1 - y1
diff2 = ray_y2 - y2
if diff1 * diff2 <= 0: # Sign change indicates intersection
# Linear interpolation to find exact intersection point
if abs(diff2 - diff1) < 1e-10:
t = 0 # Parallel lines
else:
t = diff1 / (diff1 - diff2)
x_intersect = x1 + t * (x2 - x1)
y_intersect = y1 + t * (y2 - y1)
distance = np.sqrt((x_intersect - camera_x) ** 2 + (y_intersect - camera_y) ** 2)
return x_intersect, y_intersect, distance
return None, None, None
Schritt-für-Schritt Äquivalenzklassen-Analyse:
Schritt 1: Array-Strukturklassen (x_road, y_road)
| Klasse | Beschreibung | Repräsentant | Erwartetes Verhalten |
|---|---|---|---|
| Leere Arrays | len = 0 |
x=[], y=[] |
Sollte (None, None, None) zurückgeben |
| Einzelner Punkt | len = 1 |
x=[0], y=[0] |
Kein Segment möglich → (None, None, None) |
| Zwei Punkte | len = 2 |
x=[0,10], y=[0,2] |
Ein Segment (minimal gültig) |
| Viele Punkte | len > 10 |
x=[0,10,...,100] |
Mehrere Segmente |
| Nicht übereinstimmende Längen | len(x) ≠ len(y) |
x=[0,10], y=[0] |
Fehler oder None |
Schritt 2: Winkelklassen (angle_degrees)
| Klasse | Bereich | Repräsentant | Erwartetes Verhalten |
|---|---|---|---|
| Abwärts-Winkel | -90° < angle < 0° | -45° |
Sollte Schnittpunkt finden (Strahl geht nach unten) |
| Horizontal | angle = 0° | 0° |
Horizontaler Strahl (kann schneiden oder nicht) |
| Aufwärts-Winkel | 0° < angle < 90° | 45° |
Strahl geht nach oben (wahrscheinlich kein Schnitt) |
| Vertikal abwärts | angle = -90° | -90° |
Gibt None zurück (speziell behandelt) |
| Vertikal aufwärts | angle = 90° | 90° |
Gibt None zurück (speziell behandelt) |
Schritt 3: Kamerapositionsklassen
| Klasse | Beschreibung | Repräsentant | Warum wichtig |
|---|---|---|---|
| Kamera vor Straße | camera_x < x_road[0] |
camera_x = -5 |
Strahl bewegt sich vorwärts zur Straße |
| Kamera auf Straße | x_road[0] ≤ camera_x ≤ x_road[-1] |
camera_x = 10 |
Kamera innerhalb der Straßengrenzen |
| Kamera nach Straße | camera_x > x_road[-1] |
camera_x = 100 |
Alle Segmente hinter der Kamera |
| Kamera über Straße | camera_y > max(y_road) |
camera_y = 20 |
Blick nach unten auf die Straße |
| Kamera auf Straßenhöhe | camera_y ≈ y_road[i] |
camera_y = 2.0 |
Tangenten-Fall |
| Kamera unter Straße | camera_y < min(y_road) |
camera_y = -5 |
Blick nach oben (schneidet vielleicht nicht) |
Schritt 4: Ergebnis-basierte Klassen
| Klasse | Beschreibung | Test-Szenario |
|---|---|---|
| Schnittpunkt auf erstem Segment | Strahl trifft sofort | Abwärts-Strahl, Kamera vor Straße |
| Schnittpunkt auf mittlerem Segment | Strahl trifft nach Überspringen von Segmenten | Kamera teilweise entlang der Straße |
| Schnittpunkt auf letztem Segment | Strahl trifft am Ende | Steiler Abwärts-Winkel |
| Kein Schnittpunkt | Strahl verfehlt komplett | Aufwärts-Winkel oder Kamera nach Straße |
| Mehrere mögliche Schnittpunkte | Strahl könnte mehrere Segmente treffen | Nicht möglich (gibt ersten zurück) |
Umfassende Testklasse (~25-30 Tests):
import numpy as np
from numpy.typing import NDArray
import pytest
from road_profile_viewer.geometry import find_intersection
class TestFindIntersectionEquivalenceClasses:
"""Umfassende Äquivalenzklassen-Tests für find_intersection()."""
# ============ STRUKTURELLE TESTS ============
def test_empty_arrays(self):
"""Structural class: Empty road arrays"""
x, y, dist = find_intersection(np.array([]), np.array([]), -10.0)
assert x is None, "Empty arrays should return None"
def test_single_point_road(self):
"""Structural class: Single point (no segment)"""
x, y, dist = find_intersection(np.array([5.0]), np.array([2.0]), -10.0)
assert x is None, "Single point cannot form segment"
def test_two_point_road_minimum_valid(self):
"""Structural class: Two points (one segment, minimum valid)"""
x_road = np.array([0.0, 10.0])
y_road = np.array([0.0, 2.0])
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=0.0, camera_y=5.0)
assert x is not None, "Two points should allow intersection"
def test_many_points_road(self):
"""Structural class: Many points (multiple segments)"""
x_road = np.linspace(0, 100, 50)
y_road = 0.1 * x_road # Sloped road
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=0.0, camera_y=10.0)
assert x is not None, "Many points should allow intersection"
# ============ WINKELKLASSEN-TESTS ============
def test_downward_angle_normal(self):
"""Angle class: Normal downward angle (-90° < angle < 0°)"""
x_road = np.array([0, 10, 20, 30])
y_road = np.array([0, 2, 4, 6])
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=0.0, camera_y=10.0)
assert x is not None, "Downward angle should find intersection"
assert dist > 0, "Distance should be positive"
def test_horizontal_angle(self):
"""Angle class: Horizontal ray (angle = 0°)"""
x_road = np.array([0, 10, 20])
y_road = np.array([2.0, 2.0, 2.0]) # Flat road at y=2
x, y, dist = find_intersection(x_road, y_road, 0.0, camera_x=-5.0, camera_y=2.0)
# Horizontal ray at same level as flat road - should intersect
assert x is not None, "Horizontal ray should intersect flat road at same level"
def test_upward_angle_no_intersection(self):
"""Angle class: Upward angle (0° < angle < 90°)"""
x_road = np.array([0, 10, 20])
y_road = np.array([0, 1, 2])
x, y, dist = find_intersection(x_road, y_road, 45.0, camera_x=0.0, camera_y=0.0)
# Ray goes upward, might not intersect depending on road position
# This test verifies function handles upward angles gracefully
def test_vertical_downward_angle(self):
"""Angle class: Vertical downward (angle = -90°)"""
x_road = np.array([0, 10, 20])
y_road = np.array([0, 2, 4])
x, y, dist = find_intersection(x_road, y_road, -90.0)
assert x is None, "Vertical angle should return None (implementation choice)"
def test_vertical_upward_angle(self):
"""Angle class: Vertical upward (angle = 90°)"""
x_road = np.array([0, 10, 20])
y_road = np.array([0, 2, 4])
x, y, dist = find_intersection(x_road, y_road, 90.0)
assert x is None, "Vertical angle should return None"
# ============ KAMERAPOSITIONS-TESTS ============
def test_camera_before_road(self):
"""Camera position class: Camera before road start"""
x_road = np.array([10, 20, 30])
y_road = np.array([2, 4, 6])
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=0.0, camera_y=10.0)
assert x is not None, "Camera before road should find intersection"
assert x >= 10, "Intersection should be on or after road start"
def test_camera_on_road(self):
"""Camera position class: Camera within road bounds"""
x_road = np.array([0, 10, 20, 30])
y_road = np.array([0, 2, 4, 6])
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=15.0, camera_y=10.0)
# Camera at x=15 (between 10 and 20) - should find intersection ahead
def test_camera_after_road(self):
"""Camera position class: Camera after road end"""
x_road = np.array([0, 10, 20])
y_road = np.array([0, 2, 4])
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=30.0, camera_y=10.0)
# All segments behind camera - should return None
assert x is None, "Camera after road should find no intersection"
def test_camera_above_road(self):
"""Camera position class: Camera above road (looking down)"""
x_road = np.array([0, 10, 20])
y_road = np.array([0, 1, 2]) # Road below camera
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=0.0, camera_y=20.0)
assert x is not None, "Camera above road should find intersection with downward ray"
def test_camera_at_road_level(self):
"""Camera position class: Camera at same level as road"""
x_road = np.array([0, 10, 20])
y_road = np.array([2.0, 2.0, 2.0]) # Flat at y=2
x, y, dist = find_intersection(x_road, y_road, 0.0, camera_x=0.0, camera_y=2.0)
# Camera on the road, horizontal ray - tangent case
def test_camera_below_road(self):
"""Camera position class: Camera below road (looking up)"""
x_road = np.array([0, 10, 20])
y_road = np.array([5, 5, 5]) # Road above camera
x, y, dist = find_intersection(x_road, y_road, 10.0, camera_x=0.0, camera_y=0.0)
# Upward angle might intersect road above
# ============ ERGEBNIS-BASIERTE TESTS ============
def test_intersection_on_first_segment(self):
"""Outcome class: Intersection occurs on first road segment"""
x_road = np.array([0, 10, 20, 30])
y_road = np.array([0, 5, 10, 15])
x, y, dist = find_intersection(x_road, y_road, -30.0, camera_x=-5.0, camera_y=10.0)
if x is not None:
assert 0 <= x <= 10, "Should intersect first segment"
def test_intersection_on_middle_segment(self):
"""Outcome class: Intersection occurs on middle segment (skips earlier segments)"""
x_road = np.array([0, 5, 10, 15, 20])
y_road = np.array([0, 1, 2, 3, 4])
x, y, dist = find_intersection(x_road, y_road, -5.0, camera_x=7.0, camera_y=5.0)
# Camera at x=7, segments before are behind, should hit middle segment
def test_intersection_on_last_segment(self):
"""Outcome class: Intersection on last road segment"""
x_road = np.array([0, 10, 20, 30])
y_road = np.array([5, 5, 5, 0]) # Drops at end
x, y, dist = find_intersection(x_road, y_road, -2.0, camera_x=15.0, camera_y=10.0)
# Shallow angle might only hit last segment
def test_no_intersection_ray_misses(self):
"""Outcome class: Ray doesn't intersect road at all"""
x_road = np.array([10, 20, 30])
y_road = np.array([0, 1, 2])
x, y, dist = find_intersection(x_road, y_road, 45.0, camera_x=0.0, camera_y=0.0)
# Upward ray from origin, road ahead and above - likely misses
# (Depends on exact geometry, but tests graceful handling)
# ============ STRASSENFORM-TESTS ============
def test_flat_horizontal_road(self):
"""Road shape class: Perfectly flat road"""
x_road = np.array([0, 10, 20, 30])
y_road = np.array([3.0, 3.0, 3.0, 3.0])
x, y, dist = find_intersection(x_road, y_road, 0.0, camera_x=0.0, camera_y=3.0)
# Horizontal ray at same level as flat road - tangent case
def test_sloped_road(self):
"""Road shape class: Consistently sloped road"""
x_road = np.linspace(0, 30, 10)
y_road = 0.2 * x_road # Linear slope
x, y, dist = find_intersection(x_road, y_road, -15.0, camera_x=0.0, camera_y=10.0)
assert x is not None, "Should intersect sloped road"
def test_curved_road(self):
"""Road shape class: Curved/wavy road"""
x_road = np.linspace(0, 30, 20)
y_road = 2 * np.sin(x_road / 5) + 3 # Sinusoidal curve
x, y, dist = find_intersection(x_road, y_road, -10.0, camera_x=0.0, camera_y=10.0)
assert x is not None, "Should intersect curved road"
Visuelle Illustrationen der Testfälle
Um besser zu verstehen, was diese Testfälle tatsächlich testen, visualisieren wir die Geometrie der find_intersection()-Funktion. Jede Illustration zeigt:
- Blaue Linie mit Punkten: Straßenprofil (Reihe verbundener Segmente)
- Roter Kreis: Kameraposition
- Rote gestrichelte Linie: Strahl von der Kamera im angegebenen Winkel
- Grüner Kreis: Schnittpunkt (falls gefunden)
- Grüne gepunktete Linie: Abstand von Kamera zum Schnittpunkt
Strukturelle Tests (4 Tests):
Test 1: Leere Arrays - Keine Straße zum Schneiden
Test 2: Einzelner Punkt - Kein Segment (ungültig)
Test 3: Zwei Punkte - Minimal gültige Straße (ein Segment)
Test 4: Viele Punkte (50 Punkte) - Komplexe Straße
Winkelklassen-Tests (5 Tests):
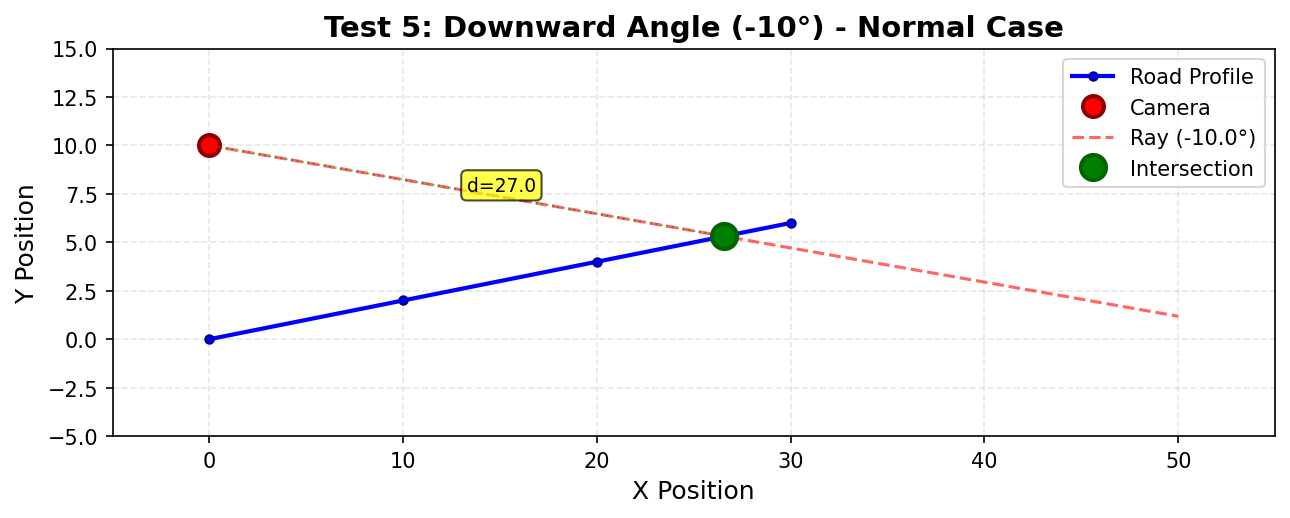
Test 5: Abwärtswinkel (-10°) - Normalfall
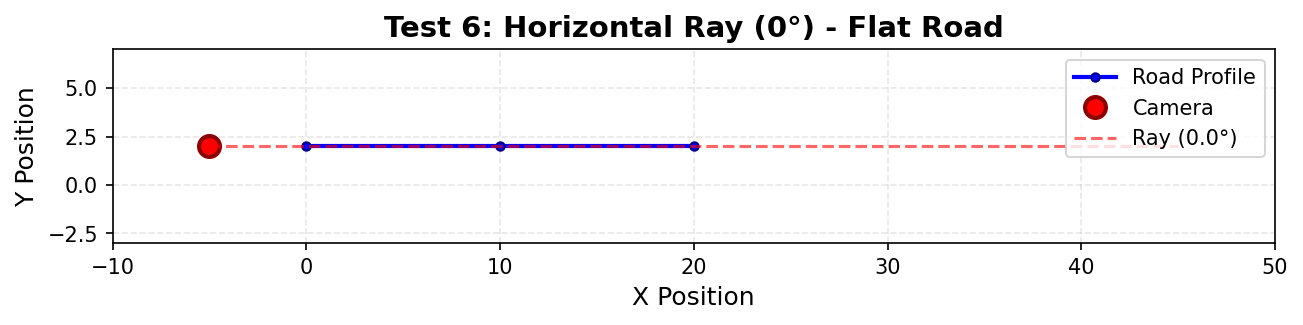
Test 6: Horizontaler Strahl (0°) - Flache Straße auf gleicher Höhe
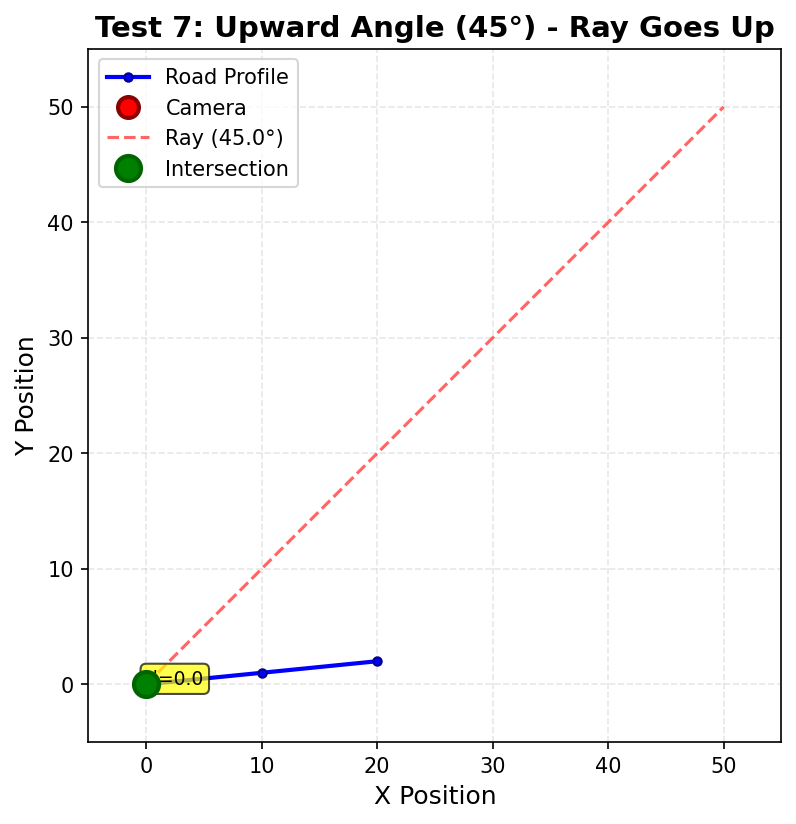
Test 7: Aufwärtswinkel (45°) - Strahl geht nach oben
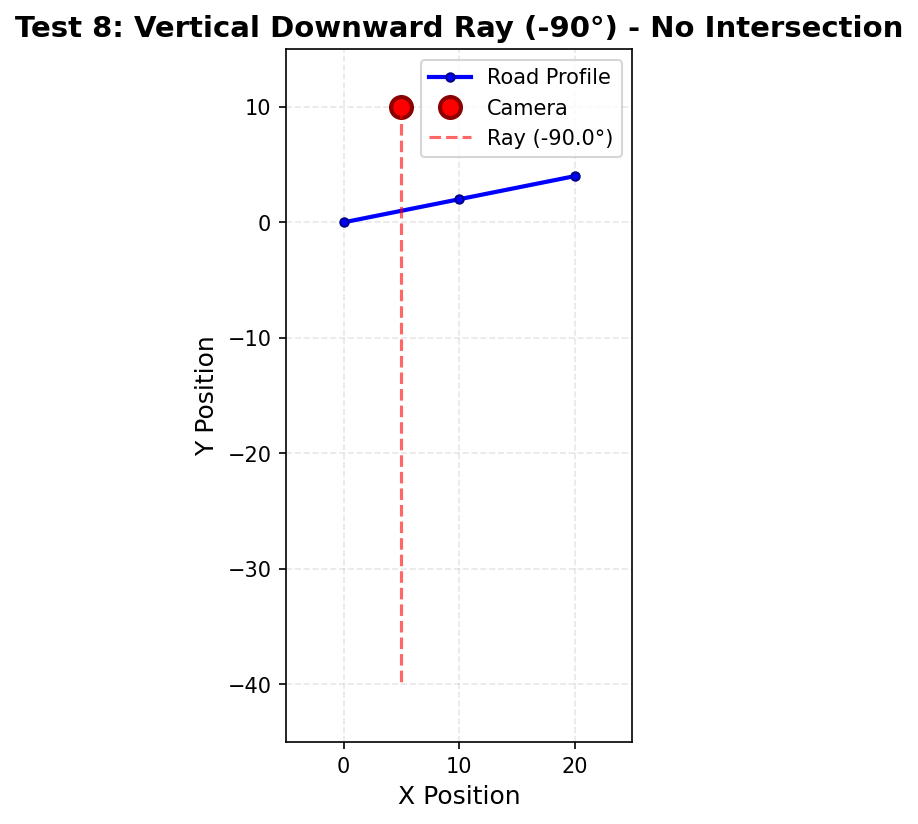
Test 8: Vertikal abwärts (-90°) - Kein Schnittpunkt
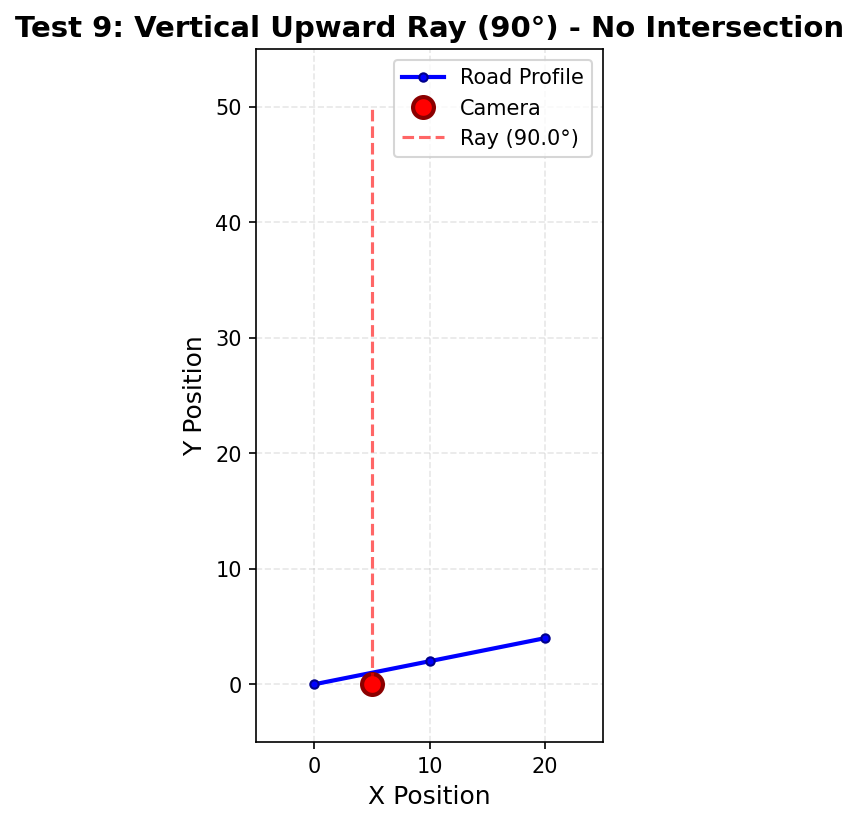
Test 9: Vertikal aufwärts (90°) - Kein Schnittpunkt
Kamerapositions-Tests (6 Tests):
Test 10: Kamera vor Straßenanfang - Strahl reist vorwärts
Test 11: Kamera auf Straße - Zwischen Segmenten
Test 12: Kamera nach Straßenende - Kein Schnittpunkt
Test 13: Kamera über Straße - Nach unten schauend
Test 14: Kamera auf Straßenhöhe - Tangente
Test 15: Kamera unter Straße - Nach oben schauend
Ergebnis-basierte Tests (4 Tests):
Test 16: Schnittpunkt am ersten Segment
Test 17: Schnittpunkt am mittleren Segment
Test 18: Schnittpunkt am letzten Segment
Test 19: Kein Schnittpunkt - Strahl verfehlt Straße
Straßenform-Tests (3 Tests):
Test 20: Flache horizontale Straße - Tangente
Test 21: Gleichmäßig geneigte Straße
Test 22: Gekrümmte/wellige Straße (sinusförmig)
Warum visuelles Testen wichtig ist:
Diese Illustrationen enthüllen Einsichten, die aus Code allein schwer zu erkennen sind:
- Geometrische Intuition: Sie können sofort sehen, ob ein Testfall physikalisch sinnvoll ist
- Grenzfälle werden offensichtlich: Tangenten-Strahlen, parallele Linien und Randbedingungen sind visuell klar
- Fehlende Testfälle: Beim Betrachten der Diagramme fallen Ihnen vielleicht Szenarien auf, die Sie vergessen haben (z.B. “Was ist, wenn die Kamera in einem Tal in der Straße ist?”)
- Debugging-Hilfe: Wenn ein Test fehlschlägt, hilft die Visualisierung zu verstehen, ob der Fehler im Test oder im Code liegt
Wichtige Erkenntnis - Gleiches Ergebnis, unterschiedliche Eingabedimensionen:
Beachte, dass Test 3 (Zwei-Punkte-Straße) und Test 13 (Kamera über Straße) beide KEINEN Schnittpunkt zeigen - der Strahl verfehlt die Straße. Aber sie testen völlig unterschiedliche Dinge!
Test 3 Mathematik:
- Kamera bei (0, 5), Strahl bei -10°
- Strahlgleichung:
y = 5 - 0,176x - Straße: (0, 0) → (10, 2), Gleichung:
y = 0,2x - Strahl und Straßenlinie würden sich bei
x ≈ 13,3schneiden - Aber die Straße endet bei x=10! → Kein Schnittpunkt
Test 13 Mathematik:
- Kamera bei (0, 20), Strahl bei -10°
- Strahlgleichung:
y = 20 - 0,176x - Straße: (0, 0) → (10, 1) → (20, 2)
- Strahl würde sich bei
x ≈ 72,5schneiden - Aber die Straße endet bei x=20! → Kein Schnittpunkt
Warum beide Tests notwendig sind:
- Test 3 validiert: “Kann die Funktion eine minimale Straßenstruktur handhaben (nur 1 Segment)?”
- Test 13 validiert: “Kann die Funktion eine Kamera handhaben, die weit über der Straße positioniert ist?”
Dies demonstriert ein entscheidendes Testprinzip: Sie müssen verschiedene Eingabedimensionen abdecken, selbst wenn sie das gleiche Ergebnis produzieren! Nur weil zwei Tests beide None zurückgeben, bedeutet das nicht, dass sie redundant sind - sie testen möglicherweise unterschiedliche Äquivalenzklassen (strukturell vs. positionell).
Praktischer Tipp: Wenn Sie komplexe geometrische Funktionen testen, erstellen Sie immer früh in der Entwicklung Visualisierungswerkzeuge. Sie zahlen sich vielfach in eingesparter Debugging-Zeit aus!
Wichtige Einsichten aus der find_intersection-Analyse:
- Komplexitäts-Explosion: Diese Funktion hat 5 Parameter mit:
- 5 strukturellen Klassen (Array-Längen)
- 5 Winkelklassen
- 6 Kamerapositionsklassen
- 4 Ergebnisklassen
- Potenzielle Kombinationen: 5 × 5 × 6 × 4 = 600 Testfälle!
- KI-Einschränkungen: Wenn Sie ein LLM bitten, “umfassende Tests für find_intersection zu schreiben”, wird es wahrscheinlich:
- ✅ Gute strukturelle Tests generieren (leer, einzeln, viele)
- ✅ Winkeltests generieren (abwärts, horizontal, vertikal)
- ❌ Kamerapositionsklassen verpassen (unter Straße, nach Straße)
- ❌ Ergebnis-basierte Klassen verpassen (Schnittpunkt auf spezifischem Segment)
- ❌ Straßenform-Klassen verpassen (flach, geneigt, gekrümmt)
- Menschliche Einsicht erforderlich: Sie müssen:
- Den Code lesen, um Logik-Verzweigungen zu verstehen
- Über geometrische Grenzfälle nachdenken (Tangente, parallel)
- Physikalische Einschränkungen berücksichtigen (Kamera hinter Straße)
- Tatsächliches Verhalten testen (gibt vertikaler Winkel wirklich None zurück?)
Praktischer Ansatz:
Sie brauchen nicht alle 600 Tests. Stattdessen:
- Decke jede Dimension ab mit mindestens 2-3 Tests
- Fokussiere auf risikoreiche Kombinationen (z.B. leeres Array + beliebiger Winkel)
- Nutze LLM für Boilerplate, Mensch für Vollständigkeit
- Ziele auf ~20-30 Tests, die wichtige Äquivalenzklassen abdecken
Das ist realistisches Testen – umfassend genug, um Bugs zu fangen, praktisch genug zum Warten!